

随着多模态大模型技术的快速迭代,视觉+文本的跨模态交互能力已经成为通用人工智能落地的核心能力之一,但长期以来,行业内针对多模态模型的评测基准大多聚焦于表层视觉信息感知能力,无法有效衡量模型整合外部结构化知识完成复杂推理的水平,成为制约多模态技术向文博、工业、教育等需要专业知识支撑的垂直场景落地的重要瓶颈。
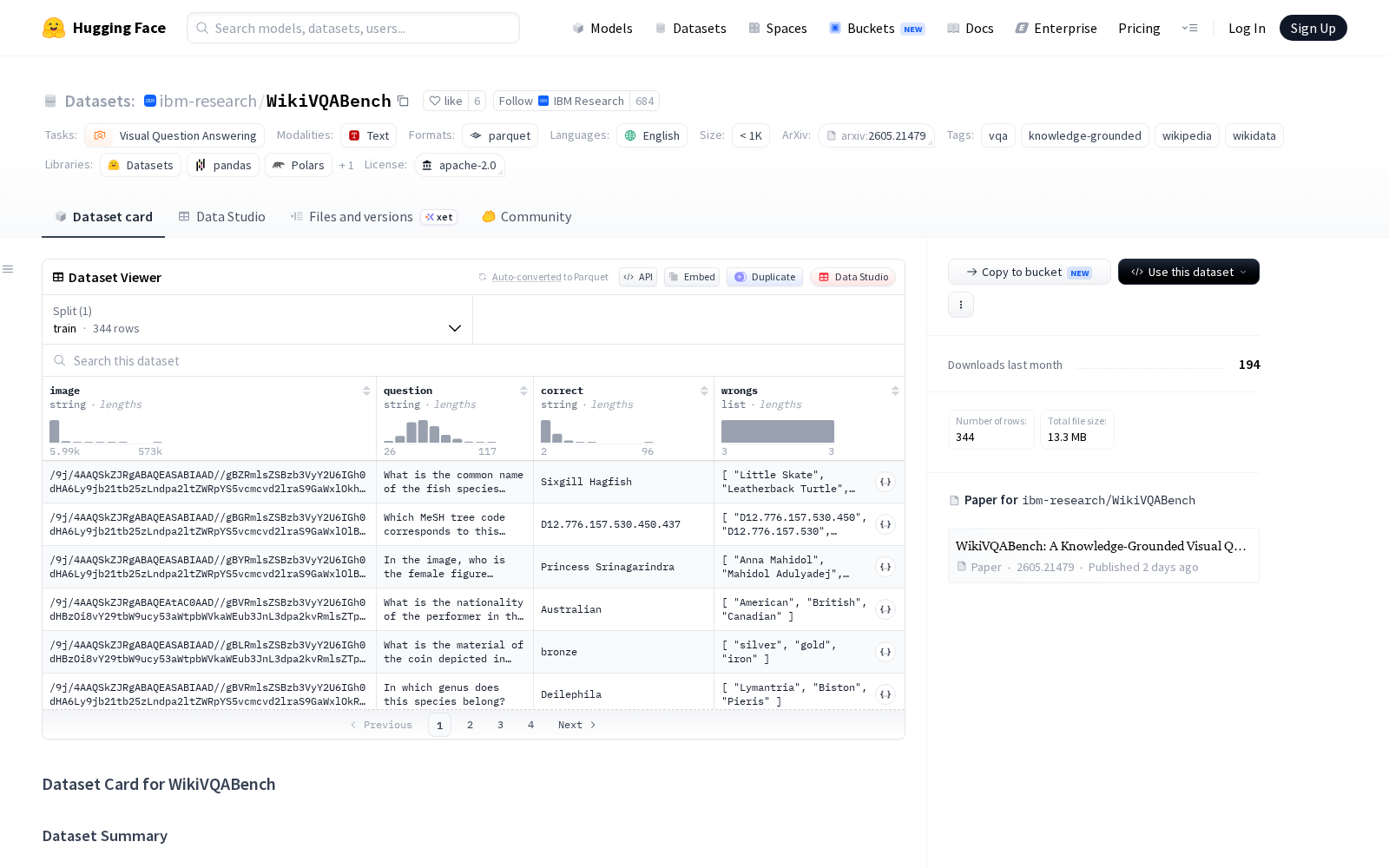
针对这一行业痛点,IBM研究院本次正式推出知识增强型视觉问答基准数据集WikiVQABench,旨在构建标准化评测体系,精准评估视觉语言模型整合外部结构化知识的能力。据介绍,该数据集包含344张维基百科公开图像及其对应的多项选择题,所有题目均无法仅通过识别图像表层信息得出答案,必须同时结合视觉证据与维基数据的结构化知识进行推理才能解答,整体数据规模适中但标注质量精良,可覆盖绝大多数常见的跨模态知识推理场景。
为保障数据集的科学性与准确性,WikiVQABench的创建采用了自动化生成与人工审核相结合的标准化流程:研发团队首先基于WIT数据集的公开图像-标题对,通过维基数据接口检索对应实体的关联关系,再借助大语言模型生成符合逻辑的候选问题,最终通过多轮人工审核校验,确保所有题目的事实准确性、视觉-文本一致性以及知识调用必要性,避免出现无效推理题或事实错误。
从应用价值来看,WikiVQABench主要用于评估知识增强型视觉语言模型在实体关联识别、多跳知识推理等核心任务中的表现,解决了传统视觉问答基准过于依赖表层感知而忽视外部知识整合能力评估的行业痛点。依托该基准数据集,研发团队可针对性优化多模态模型的知识调用能力,相关技术成熟后可落地于多个垂直场景:例如智慧文博领域,游客拍摄文物即可获得关联的历史背景、出土信息等专业知识;工业巡检场景中,拍摄设备部件即可结合工业知识库自动判断故障类型、给出维修建议;科普教育场景中,拍摄动植物、自然景观即可调用百科知识给出专业科普内容,大幅降低专业知识的获取门槛。
作为全球首个聚焦知识增强视觉问答方向的公开基准数据集之一,WikiVQABench的推出也将进一步完善多模态大模型的评测体系,推动多模态技术从“感知能力迭代”向“认知能力升级”演进,为数据要素驱动的人工智能技术研发提供更精准的方向指引。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)