

当前生成式AI尤其是文生图、多模态大模型技术迭代速度不断加快,但训练数据的质量、规模与合规性一直是制约行业发展的核心瓶颈——现有公开图文数据集普遍存在样本冗余度高、标注精度参差不齐、安全风险隐患突出等问题,中小研发团队往往难以负担高质量数据集的采集与清洗成本,也在一定程度上阻碍了生成式AI领域开放、可复现研究的推进。
近日,Jasper Research正式发布大规模开源文本-图像数据集MONET,该数据集于2026年5月20日首发于学术平台arXiv,主要面向文本-图像生成、生成式AI训练数据构建等领域开放使用。
据介绍,MONET共包含约1.049亿对高质量图像-文本样本,是团队从29亿原始图文对中经过多阶段严格筛选产出的成果:筛选流程覆盖安全性过滤、重复样本排查、垂直领域定向筛选多个环节,同时团队引入多种主流视觉语言模型对样本进行重新标注,形成了覆盖简短概念描述、场景属性标注、精细化内容说明的多层次文本标注体系。整个数据集构建过程整合了美学评分、多分类器安全检测、感知哈希去重等多项前沿数据治理技术,还补充了由Apache 2.0许可模型生成的合成样本,兼顾了样本丰富度与使用合规性。
该数据集的推出,核心目标是降低大规模文本-图像模型的研究门槛,解决现有公开数据集的共性痛点。从潜在应用场景来看,MONET除了可用于训练通用级大规模文本-图像生成模型外,还可作为多模态理解模型的预训练数据底座、文生图效果评测的基准数据集,也可为电商商品智能作图、传媒内容创意生成、工业设计效果图快速生成等垂直领域的定制化模型研发提供数据支撑,同时其严格的安全过滤机制也能为生成式AI内容合规治理相关研究提供参考。
作为当前公开市场上少有的亿级规模、高质量标注的开源图文数据集,MONET的发布将进一步丰富生成式AI领域的公共数据供给,推动更多中小机构、学术团队参与生成式AI技术创新,助力整个生成式AI产业的普惠化、规范化发展。
Dataset card内容:
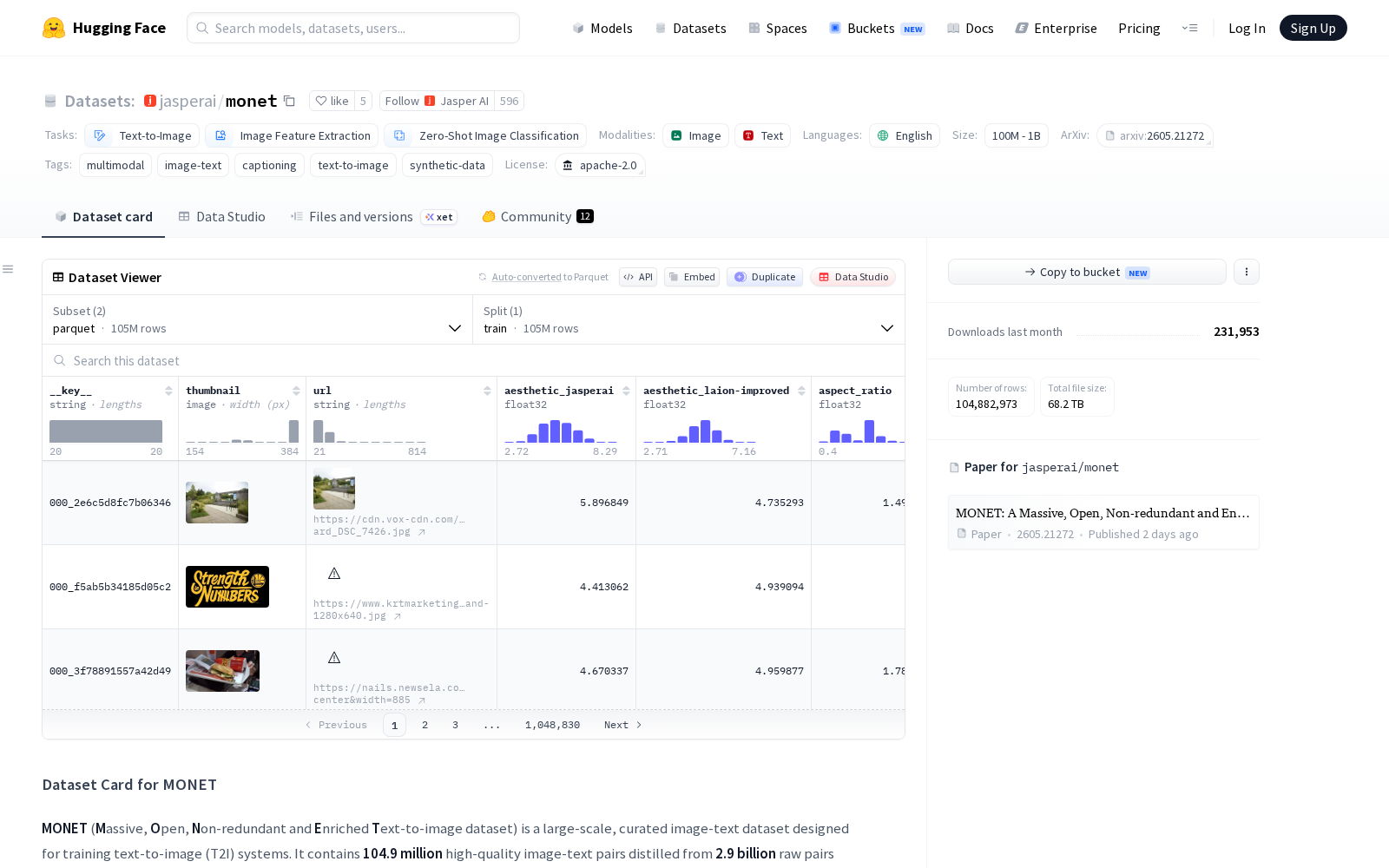
Files and versions内容:



_1769672084863.jpg)