

随着生成式AI与语音交互技术的快速落地,自动语音识别(ASR)已经成为智能客服、车载交互、智能家居、同声传译等多个数字化场景的核心基础技术,模型迭代效率也从以往的季度级提速至月度甚至周级。作为语音AI研发过程中验证模型性能、校准迭代方向的核心工具,标准化评测数据集的供给质量直接影响行业的研发效率,但当前行业内公开测试集普遍存在数据污染、评测维度单一等问题,私有评估数据集的供给缺口持续扩大。
近日,AI数据服务商Trelis正式在HuggingFace平台首发fleurs-en-test数据集,为英语ASR领域的评测提供了全新的权威参考。据介绍,fleurs-en-test是面向自动语音识别基准测试的私有评估数据集,源自Google推出的FLEURS(Few-shot Learning Evaluation of Universal Representations of Speech)跨语言ASR基准项目,具体采用其美式英语(en_us)配置的测试分割内容。作为全球公认的权威跨语言语音评测基准,FLEURS覆盖102种语言,核心定位是评估通用语音表示的少样本学习性能,此前已经被全球数千家科研机构与企业用于语音技术研发验证。
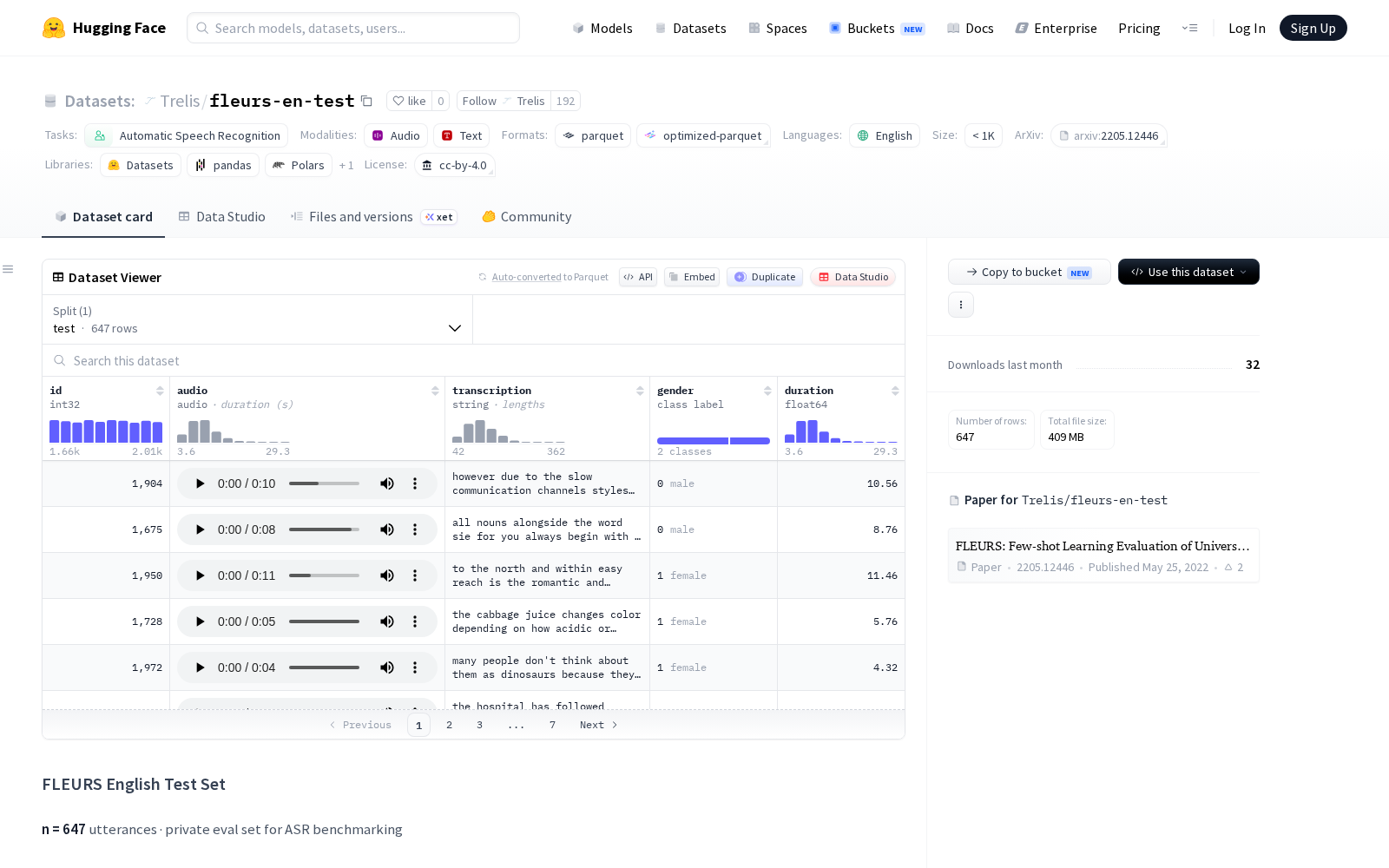
本次发布的fleurs-en-test数据集共包含647个语音话语样本,数据构建过程中未进行任何过滤或子采样,完全保留了原始FLEURS en_us测试分割的全部内容,确保了评测基准的一致性与权威性。每个样本包含五大核心字段:audio字段以原始字节形式存储语音录音,规避了编解码器转换带来的精度损失,确保评测结果不受音频预处理环节干扰;transcription为标准参考文本,可直接用于计算模型识别的准确率与错误率;id为原始FLEURS话语的唯一标识符,方便研发人员对齐原始基准数据开展交叉验证;gender字段标注了说话者性别,duration字段标注了语音持续时间,两大标签为细分场景的性能评测提供了支撑。
从应用价值来看,该数据集采用CC-BY-4.0许可证,使用者只需注明来源即可免费商用与学术使用,大幅降低了语音AI研发团队的评测成本。该数据集可广泛应用于多个场景:一是通用英语ASR模型的上线前校验,避免训练数据与测试数据重合导致的性能虚高问题;二是跨厂商、跨模型的统一对标,为行业评测提供统一的参考标准;三是专项语音技术的效果验证,依托性别、时长等标签可针对性测试模型在细分场景下的表现,优化迭代方向;此外也可用于少样本语音识别、语音降噪等前沿技术的研究验证。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)