

随着多模态大模型的快速落地,自动语音识别(ASR)作为人机交互、内容数字化的核心技术,其垂直场景适配需求持续攀升。当前公开语音数据集多以干净朗读式内容为主,针对议会、政务会议等带有即兴发言、专业术语、口语停顿、修正表述等特征的场景,现有数据集普遍存在标注精度不足、缺少时序定位信息等问题,直接用于模型微调极易出现领域适配性差、通用能力退化等痛点。
针对这一行业痛点,AI数据集研发商Trelis于2026年5月22日在全球AI开源社区HuggingFace正式发布VoxPopuli-Platinum-en英文语音数据集。据介绍,该数据集是专为ASR模型微调设计的高质量垂直领域语音资源,源自Meta开源的facebook/voxpopuli数据集英语子集,经Trelis自研的专有多阶段质量过滤流程处理,经验证可显著提升模型在对应场景测试集上的识别性能。
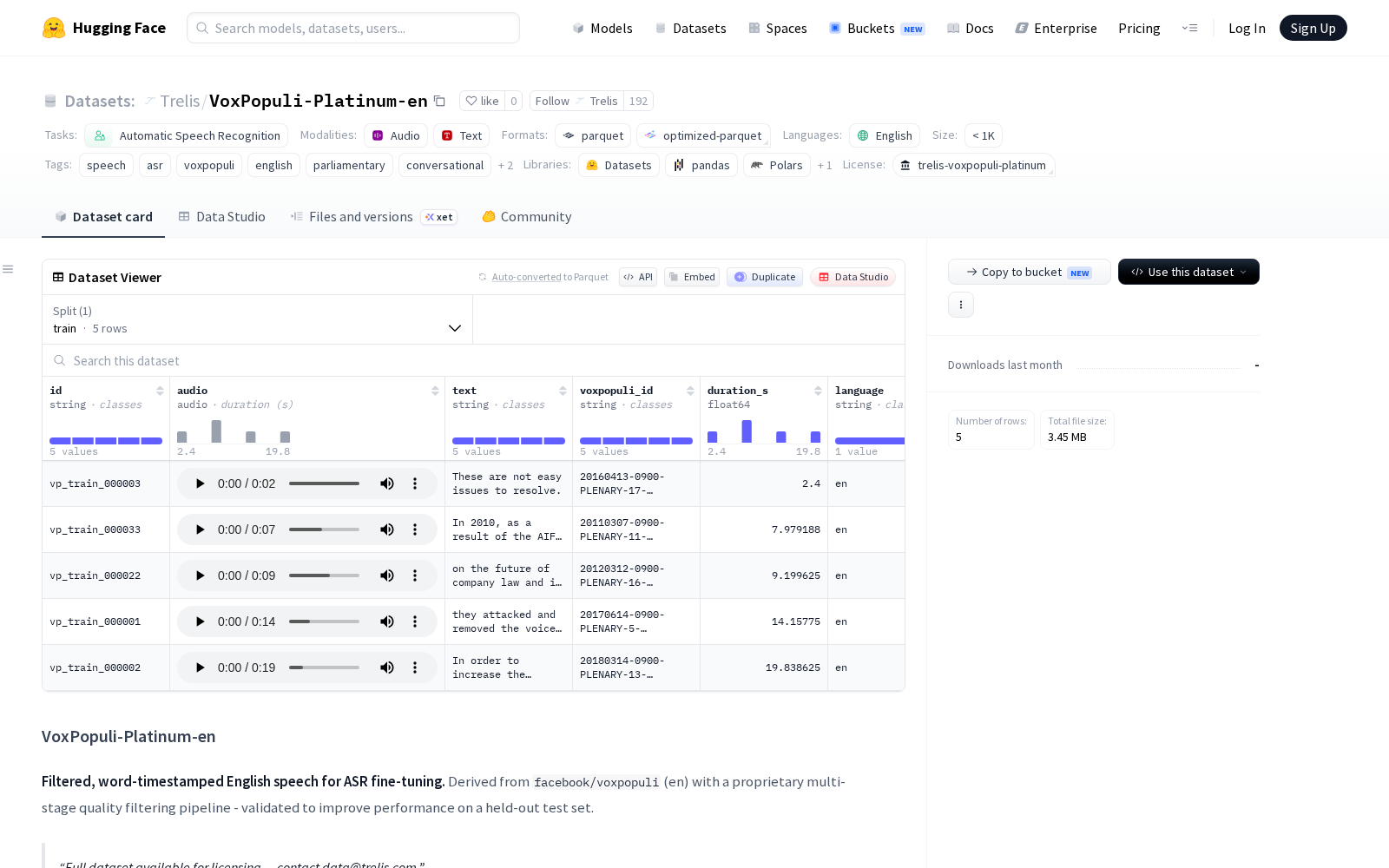
目前公开信息显示,VoxPopuli-Platinum-en数据集规模介于10万到100万样本之间,包含约100小时原始语音,所有音频均为适配主流ASR训练要求的16kHz单声道格式。每个样本附带7类结构化字段:包括唯一标识符(id)、音频文件(audio)、经过人工校验精炼的转录文本(text)、原始数据集对应ID(voxpopuli_id)、音频时长(duration_s)、语言代码(固定为en),以及核心的词级时间戳列表(word_timestamps)——后者可提供每个词汇的对应文本、开始时间、结束时间和对齐置信度得分,为语音内容的精准定位、片段剪辑、时序追溯提供了数据基础。音频内容以议会演讲、议事对话为主,保留了原始数据基于短语边界的分段风格,最大程度还原了正式会议场景的口语表达特征。
该数据集的核心价值在于解决了ASR模型垂直微调的两大普遍问题:一方面可针对性提升模型对议会领域专业表述、口语化不流利表达的识别准确率,另一方面可显著降低模型微调后在干净朗读类领域外数据上的性能退化,避免模型出现“偏科”问题。从应用场景来看,该数据集除了用于议会场景ASR模型微调之外,还可支撑政务公开语音内容的智能检索、跨境正式会议的同传预处理、会议发言的语义分析与议题统计等多类数字化需求,为政务数字化、会议智能化等领域的应用落地提供高质量数据底座。为方便开发者评估模型优化效果,该数据集还同步附带了领域内专有测试集和公开领域外测试集。
值得注意的是,该数据集的原始音频源采用CC0许可,但本次发布的精炼衍生版本需获得商业许可方可使用,官方明确禁止二次分发。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)