

当前,具身智能与服务机器人、工业协作机器人赛道正进入技术快速迭代期,机器人模仿学习、视觉伺服控制等核心技术的研发,高度依赖动作参数与视觉感知对齐的高质量场景化数据集,但此前公开领域面向细分机器人类型的标注数据集供给相对稀缺,成为制约中小研发团队技术落地的核心瓶颈之一。近日,人工智能数据集社区tomato-store正式发布eval_smolvla_data_0523_v6_multi_local专用数据集,并于2026年5月24日率先上线HuggingFace平台,面向全球研发人员开放使用。
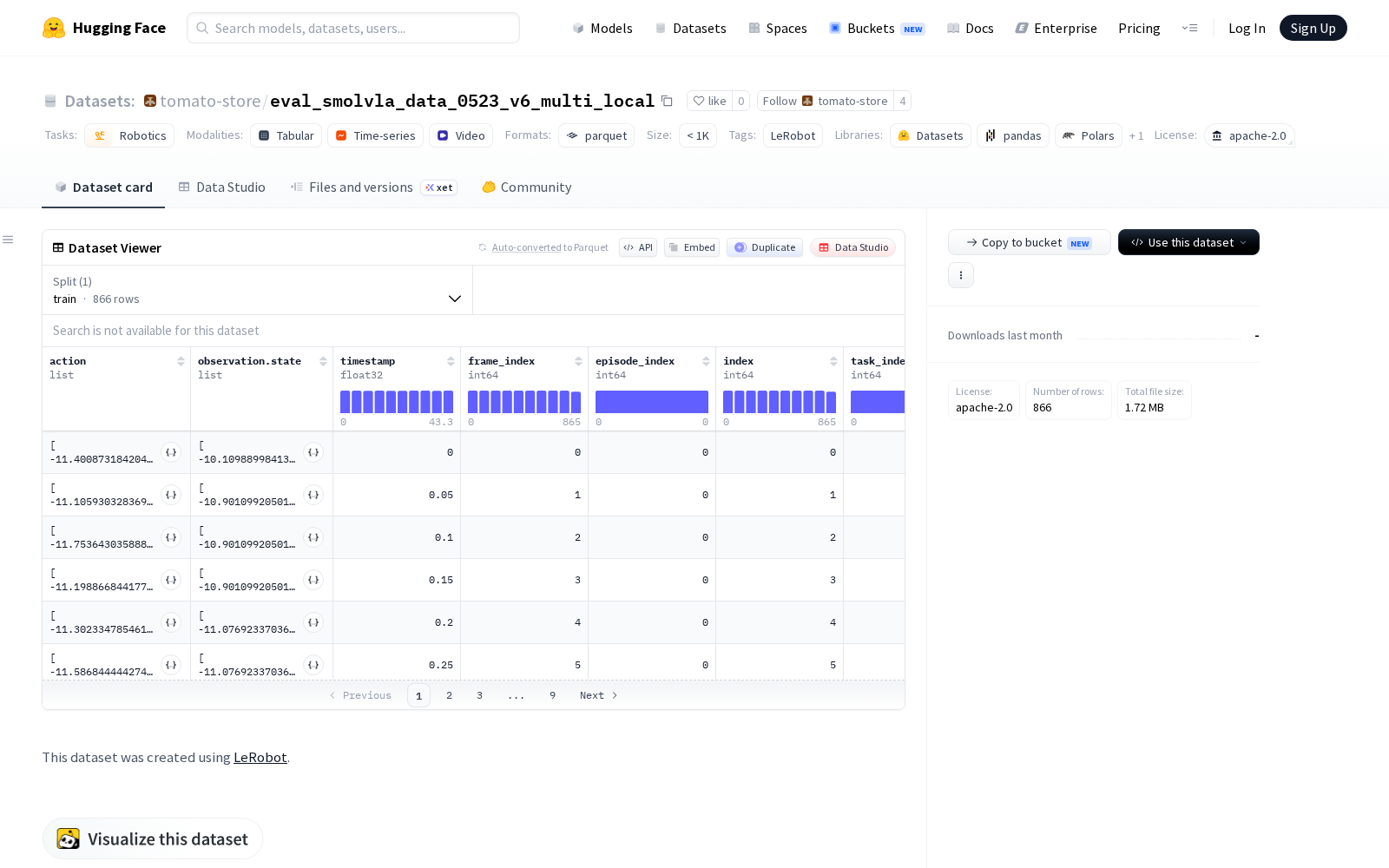
据介绍,该数据集基于LeRobot框架构建,专为bi_so_follower类型机器人的研发需求设计,聚焦机器人学核心任务场景,整体包含1个总情节、866个总帧、1个总任务,结构化数据采用parquet格式存储,视频素材采用mp4格式存储,兼顾了数据读取效率与兼容性。数据集的标注维度覆盖机器人研发全链路需求:既包含左右肩、肘、腕、夹爪位置等核心动作参数,也包含对应的观察状态数据,同时搭载3个不同视角的摄像头图像素材,分辨率分别为480x640和360x640,采样帧率达每秒20帧,配套时间戳、帧索引、情节索引、任务索引等完整标识字段,所有特征的数据类型和结构均有明确标注,可直接适配机器人控制、多模态视觉任务的训练与评测需求。
从应用场景来看,该数据集首先可支撑机器人模仿学习领域的研发工作:研发人员可基于这套动作与视觉高度对齐的标注数据,训练机器人精准复刻示教动作,尤其是双臂协作类的精细化操作任务,大幅降低模型训练的数据采集成本,提升动作复现的精度与稳定性。其次在视觉伺服控制领域,多视角实时画面与关节动作数据的绑定标注,可为视觉反馈到动作输出的闭环控制算法研发提供基准测试素材,助力研发团队优化动态场景下机器人的响应速度与误差控制能力。此外,该数据集也可作为通用评测基准,用于横向验证不同具身智能算法在同一场景下的性能表现,推动行业研发标准的统一。
作为垂直场景的专用数据资产,本次发布的机器人数据集进一步丰富了公开领域的具身智能数据供给,对于降低具身智能赛道研发门槛、推动开源协作生态建设、加快机器人控制技术从实验室走向商业化落地均有积极意义,也为数据要素在人工智能垂直赛道的价值落地提供了典型样本。
查看eval_smolvla_data_0523_v6_multi_local
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)