

随着AlphaFold等AI模型将蛋白质结构预测精度推向实用化水平,高质量、标注规范的残基级蛋白质结构数据集,已成为计算生物学、AI生命科学领域最核心的研发基础资源之一。作为MIT聚焦原子、分子尺度力学规律与跨学科应用研究的顶尖实验室,LAMM长期深耕计算生物、生物材料、分子模拟等交叉领域,其发布的公开数据集通常具备标注精度高、场景适配性强的特点,已成为全球相关领域研究的重要参考基准。本次LAMM发布的protein-secondary-structure-nppe2(又称NPPE-2蛋白质二级结构预测数据集),最初为印度理工学院马德拉斯分校深度学习与生成AI课程的蛋白质二级结构预测竞赛设计,核心任务是支撑研发者在残基水平完成蛋白质二级结构的预测任务。
该数据集采用行业通用的两类分类标注体系:第一类为八态分类(Q8/sst8),基于DSSP符号体系,涵盖H(α螺旋)、C(卷曲/环)、E(β链)、T(转角)、S(弯曲)、G(3-10螺旋)、B(β桥)和I(π螺旋)8类结构标签;第二类为三态分类(Q3/sst3),将八态标签进一步聚合为C(卷曲,包含C、T、S)、H(螺旋,包含H、G、I)和E(链,包含E、B)3类,适配不同精度需求的算法训练场景,数据集的官方评估指标为Q8和Q3宏F1分数的调和平均数。
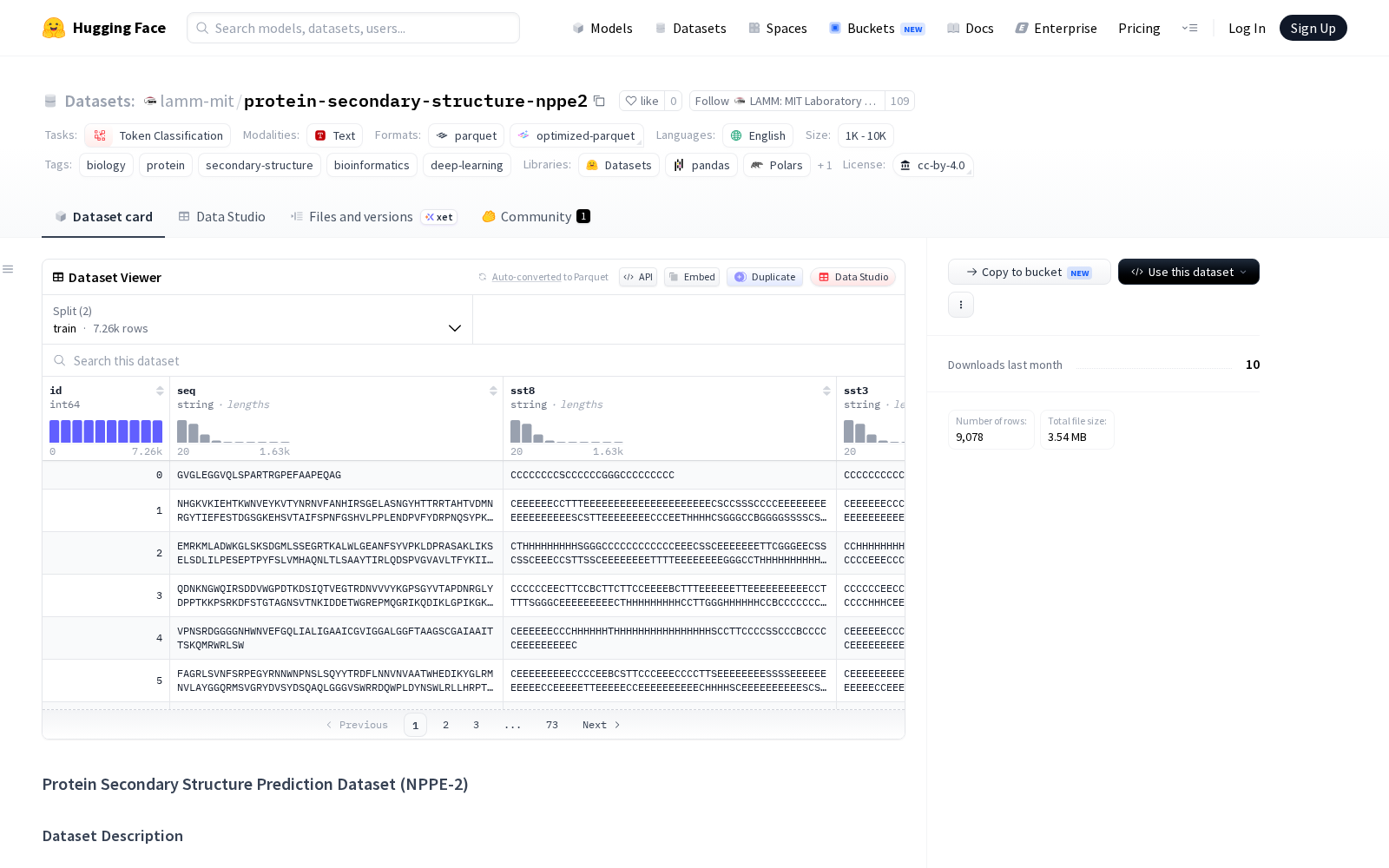
从数据体量来看,NPPE-2数据集分为训练集与测试集两部分,其中训练集包含7262个蛋白质序列,覆盖1763921个残基;测试集包含1816个序列,暂未公开标签,用于竞赛与算法评测的盲测场景。数据集覆盖的蛋白质序列长度范围为20至1632个残基,平均长度为242.9个残基,覆盖了绝大多数常规功能蛋白的长度区间。从标签分布来看,Q8分类中H(α螺旋)占比最高达31.6%,其次是C(24.2%)和E(21.0%);Q3分类中C(卷曲)占比最高达42.6%,其次是H(螺旋,35.4%)和E(链,22.1%),标签分布符合天然蛋白质的结构分布规律,训练数据的代表性较强。
目前该数据集以CSV文件形式开放下载,训练集文件包含id(唯一序列标识符)、seq(由20种标准氨基酸组成的序列)、sst8(Q8标签)和sst3(Q3标签)四列;测试集文件包含id和seq两列,方便研发者快速接入训练流程。从应用价值来看,NPPE-2不仅可用于蛋白质二级结构预测竞赛的算法比拼,还可广泛适配各类标记分类任务:在基础研究层面,可支撑蛋白质结构预测算法的迭代优化、不同蛋白质功能域的识别、突变体结构稳定性预测等生物信息学研究;在产业应用层面,可作为训练数据支撑AI辅助靶点结构解析、多肽药物分子设计、酶工程改造等生命科学研发场景,降低相关领域的训练数据获取门槛,为全球计算生物学领域的跨机构算法评测提供了统一的公开基准。
查看protein-secondary-structure-nppe2
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)