

当前,AI驱动的生物信息学研发已经进入爆发期,蛋白质结构预测作为药物研发、合成生物学等前沿领域的核心基础环节,对高质量标注训练数据的需求持续攀升。公共科研数据集的开放共享,正是降低领域研发门槛、加速技术迭代的核心支撑。近日,麻省理工学院原子与分子力学实验室(MIT Laboratory for Atomistic and Molecular Mechanics, 简称LAMM)正式发布protein-secondary-structure-netsurfp数据集,该数据集于2026年5月25日首发于开源模型社区Hugging Face,面向全球科研人员与产业团队开放使用。
作为全球顶尖的原子、分子尺度力学与交叉学科研究机构,MIT LAMM长期深耕生物分子模拟、蛋白质结构-功能关联预测等方向,此前已推出多项面向生物信息学领域的开源工具与数据集,在学界与产业界拥有广泛影响力。本次推出的数据集全称为NetSurfP-3.0 Secondary-Structure Splits,最初是为Protein-I-JEPA探针的训练与评估场景专门设计,同时可适配各类监督式蛋白质二级结构预测任务。
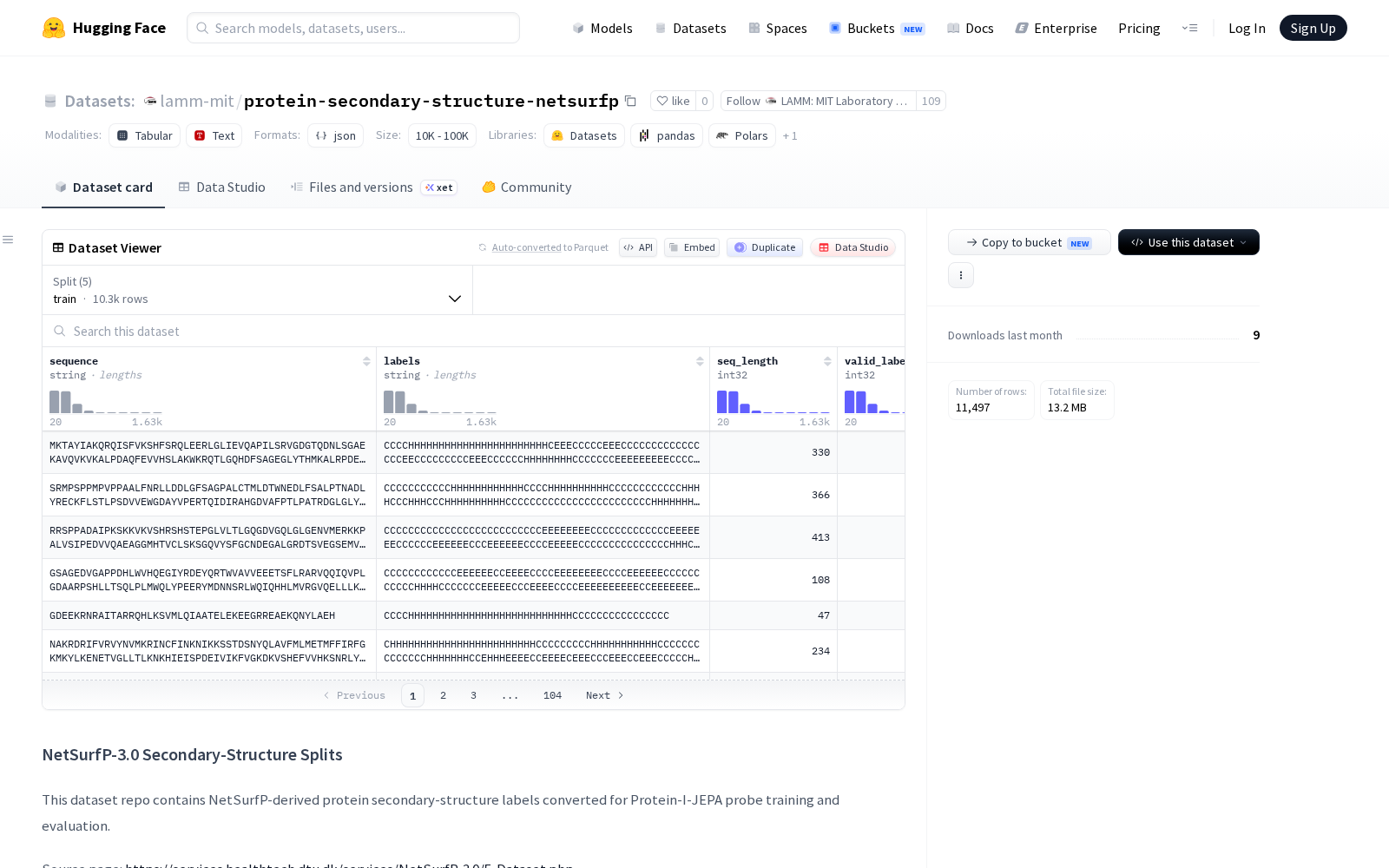
据公开信息显示,该数据集的原始数据来源于NetSurfP-3.0在线服务的预测结果,采用hhblits配置文件生成,覆盖10348条训练样本、500条验证样本,以及cb513、ts115、casp12三个外部测试集,分别包含513条、115条、21条样本,总样本量超过1.1万条。其标签体系采用行业通用的三级(Q3)二级结构标注规则:用“H”标识螺旋结构、“E”标识β链结构、“C”标识卷曲或其他结构,特殊符号“.”则标注为损失计算与准确度评估环节需要忽略的残基。每条样本包含序列、标签、序列长度、有效标签计数、所属分割、标签模式6类字段,可直接对接主流深度学习框架,无需额外预处理即可用于模型训练、超参数调优、性能评估全流程。
从应用价值来看,该数据集可覆盖多个前沿研发场景:在基础研究领域,科研团队可基于该标准化数据集开展蛋白质二级结构预测算法的优化迭代,统一的测试集划分也能让不同算法的性能对比更具公允性,减少数据差异带来的评估误差;在生物制药领域,该数据集可支撑靶点蛋白结构解析相关的模型训练,二级结构预测结果可大幅缩小蛋白质三维结构预测的搜索空间,加快靶点验证、先导化合物筛选的研发效率;在合成生物学领域,研发团队可借助基于该数据集训练的模型,预判人工设计的氨基酸序列对应的二级结构,进而调整序列参数,更快获得具备预期催化功能、结合能力的人工蛋白、人工酶。
业内分析指出,当前生物信息学领域的高质量标注数据仍存在供给不足、标注标准不统一等问题,MIT LAMM本次开放的标准化数据集,进一步完善了全球蛋白质结构研究领域的公共数据供给体系,不仅为中小科研团队、初创企业降低了研发的数据获取成本,也为整个领域的技术迭代提供了统一的基准参考,将间接推动AI药物研发、合成生物学等下游产业的落地进程。
查看protein-secondary-structure-netsurfp
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)