

当前,对话式AI正加速从纯文本交互向语音+文本融合的多模态交互升级,智能客服、数字人对话、车载语音助手、智能家居交互等场景对跨模态对话理解能力的需求持续提升,而标注规范、适配不同研发场景的高质量多模态对话数据集,是支撑相关模型研发、验证的核心基础资源。在此背景下,2026年5月25日,trl internal testing正式推出zen-audio多模态对话数据集,并首发上线HuggingFace平台,面向全球AI研发人员开放使用。
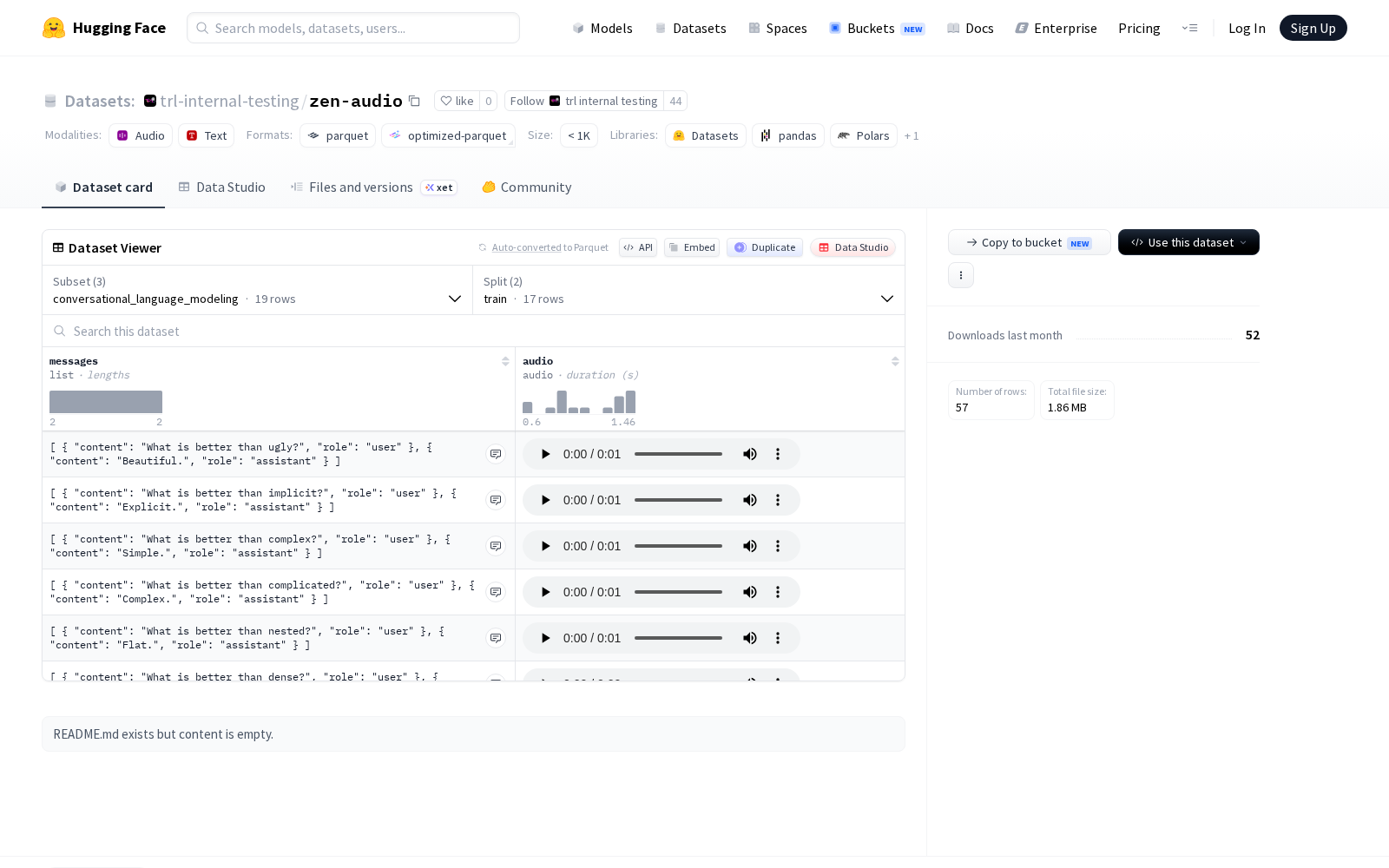
据介绍,zen-audio是专为对话式语言建模及相关任务研发设计的多配置、多模态对话数据集,目前共设置三种不同的数据组织配置,分别为conversational_language_modeling、conversational_prompt_completion 和 conversational_prompt_only,每种配置均完成了训练集与测试集的标准化分割,可适配不同类型的模型训练与评估需求。核心数据覆盖文本、音频两种模态:文本部分以结构化对话消息形式组织,每条消息均包含content(文本内容)和role(发言者角色)字段,可直接用于对话上下文理解、角色一致性校验等相关任务训练;音频部分统一采用16kHz采样率存储,可满足绝大多数语音识别、多模态对齐算法的输入要求。数据规模方面,各配置的训练集包含17个样本,测试集包含2个样本,总数据量在数百KB级别,轻量化的特性使其尤其适合小样本学习、模型原型快速验证等轻量化研发场景。
从应用场景来看,zen-audio可广泛适配多类对话AI研发需求:其一可用于对话生成模型的训练与评估,尤其是小样本场景下的特定对话风格、角色设定的生成效果验证;其二可支撑语音-文本多模态模型的研发,为端到端语音对话交互模型的跨模态对齐、上下文理解能力训练提供标准化素材,相关成果可落地于智能客服、随身语音助手、车载交互、数字人实时对话等场景;其三可用于提示-补全(prompt-completion)等序列到序列学习任务的研究,为多轮对话的指令遵循、上下文关联推理等能力验证提供基准测试数据。
作为数据要素市场中AI训练数据细分领域的新增供给,zen-audio的发布进一步丰富了多模态对话场景的数据集供给体系,尤其填补了小样本轻量化多模态对话数据集的供给空白,可为相关学术研究、产业端原型快速验证提供标准化的基础资源,助力多模态对话AI技术的迭代与落地。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)