

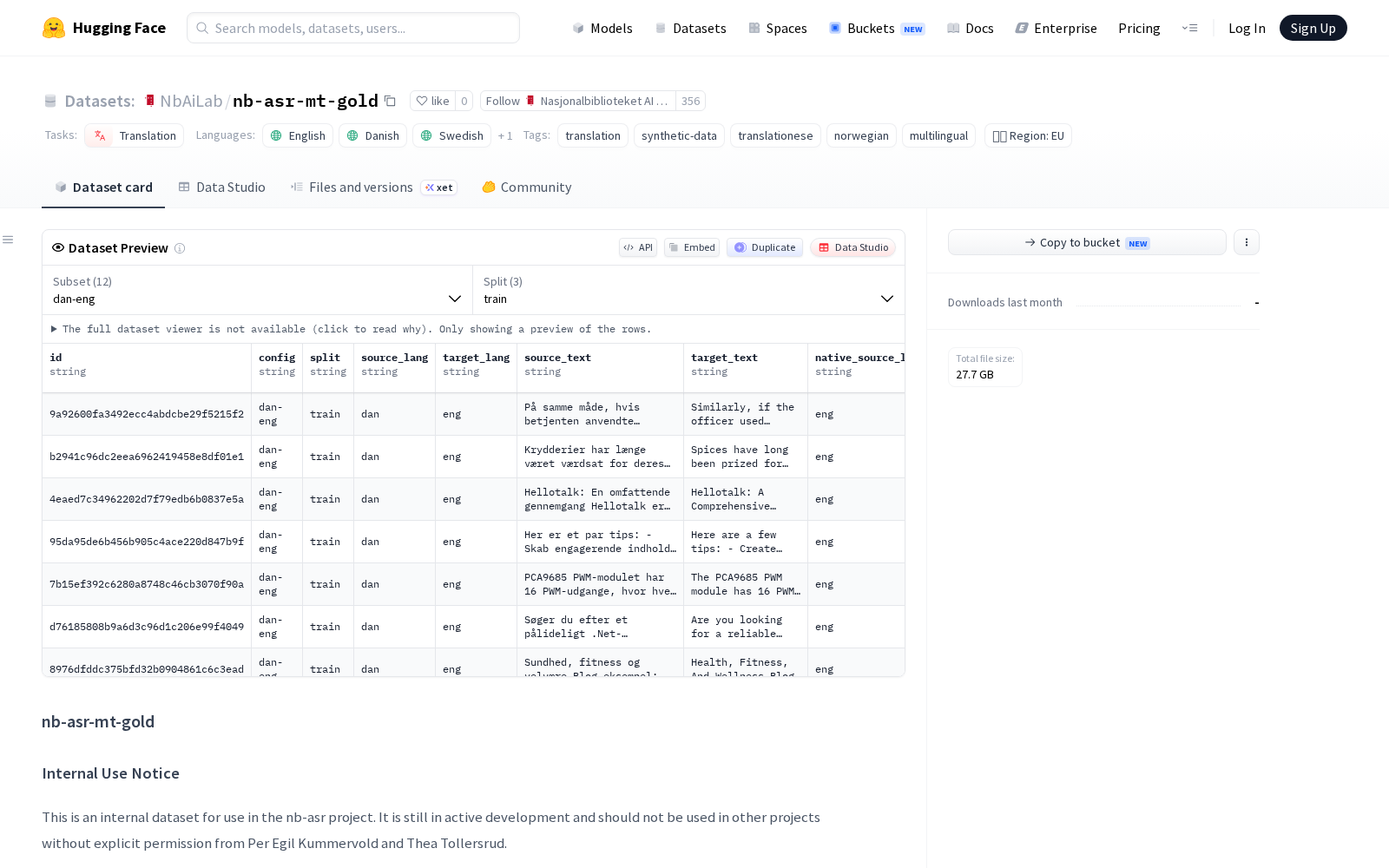
Nasjonalbiblioteket AI Lab本次发布的数据集nb-asr-mt-gold,nb-asr-mt-gold是一个基于NB-ASR翻译语料库管道生成的机器翻译清单数据集,专门用于机器翻译训练和翻译语料库感知数据构建研究。该数据集包含12个语言对配置,涵盖英语(eng)、丹麦语(dan)、瑞典语(swe)和挪威语(nob)之间的双向翻译。 数据集的核心构建理念采用反向合成数据使用策略:当一种语言(X)的母语文本被翻译成合成语言(Y)时,生成的数据行被用作从语言Y到语言X的训练样本。因此,监督目标始终是地道的母语文本,而源端文本可能保留翻译过程中产生的翻译语料库特征。 该数据集是经过严格过滤的“黄金”变体,通过多语言嵌入模型对母语原始文本和同语言回译文本进行相似度评估,仅保留高度相似的样本,旨在提供高置信度的训练数据,注重有用的覆盖范围而非严格的字符串一致性。 数据总规模为3,397,227行,按照95%训练集、2.5%验证集和2.5%测试集的比例进行确定性分割。每个配置包含详细的样本统计,其中规模较大的配置包括eng-nob(568,812行)、dan-nob(569,273行)和swe-nob(574,352行)。 数据生成过程使用了四种模型家族进行翻译路径生成,并采用不同模型进行回译。数据集保留了模型ID、版本信息、验证元数据、使用元数据、时间元数据、母语原始文本、枢轴翻译文本和回译文本等丰富字段。 该数据集主要适用于机器翻译模型训练,使用时以source_text作为模型输入,target_text作为监督学习的母语目标输出。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)