

当前全球大语言模型研发快速推进,机器翻译作为跨语言信息交互的核心基础设施,其译文流畅度、母语化程度一直是行业核心痛点,尤其是丹麦语、瑞典语、挪威语等北欧小语种,由于可用高质量平行语料规模有限,相关翻译模型的输出普遍存在翻译腔重、本地化不足等问题。作为北欧地区核心的数字人文与语言AI研究机构,挪威国家图书馆(Nasjonalbiblioteket)AI实验室依托馆藏海量多语言资源,长期深耕北欧语言的语音识别、机器翻译技术研发,本次发布的nb-asr-mt-filtered正是其NB-ASR项目的核心配套语料成果,最初为项目内部训练使用,目前仍处于持续迭代的活跃开发阶段。
该数据集的核心创新点在于采用了反向合成数据的构建逻辑:不同于传统平行语料直接收集X语言到Y语言的翻译结果作为训练样本,nb-asr-mt-filtered先将X语言的母语文本翻译为合成版Y语言文本,再将合成Y语言作为输入源、X语言母语作为监督目标进行训练,从训练规则层面降低翻译腔对最终模型效果的影响,监督目标始终为原生母语表达,仅源端可能保留翻译腔伪影。
为了避免合成数据常见的源目标不匹配、幻觉、截断等问题,该数据集在基础版本nb-asr-mt(仅完成基础非空校验、语种识别护栏校验)的基础上,额外应用了保守的多语言双语文本嵌入完整性过滤器,可有效移除明显的幻觉内容、截断伪影、解析错误和语种识别错误等低质量数据,同时最大程度保留语料覆盖范围。本次语料生成共调用了四大主流翻译大模型能力,包括谷歌推出的translategemma-4b-it、translategemma-12b-it,加泰罗尼亚超级计算中心研发的BSC-LT/salamandraTA-7b-instruct,以及阿里巴巴通义千问团队的Qwen/Qwen3.6-35B-A3B-FP8,在Olivia框架下完成全量翻译路线生成与回译校验。数据集最终按照(配置,源块ID)的规则进行拆分,采用95%训练集、2.5%验证集、2.5%测试集的通用比例划分,适配绝大多数机器翻译模型的训练需求。
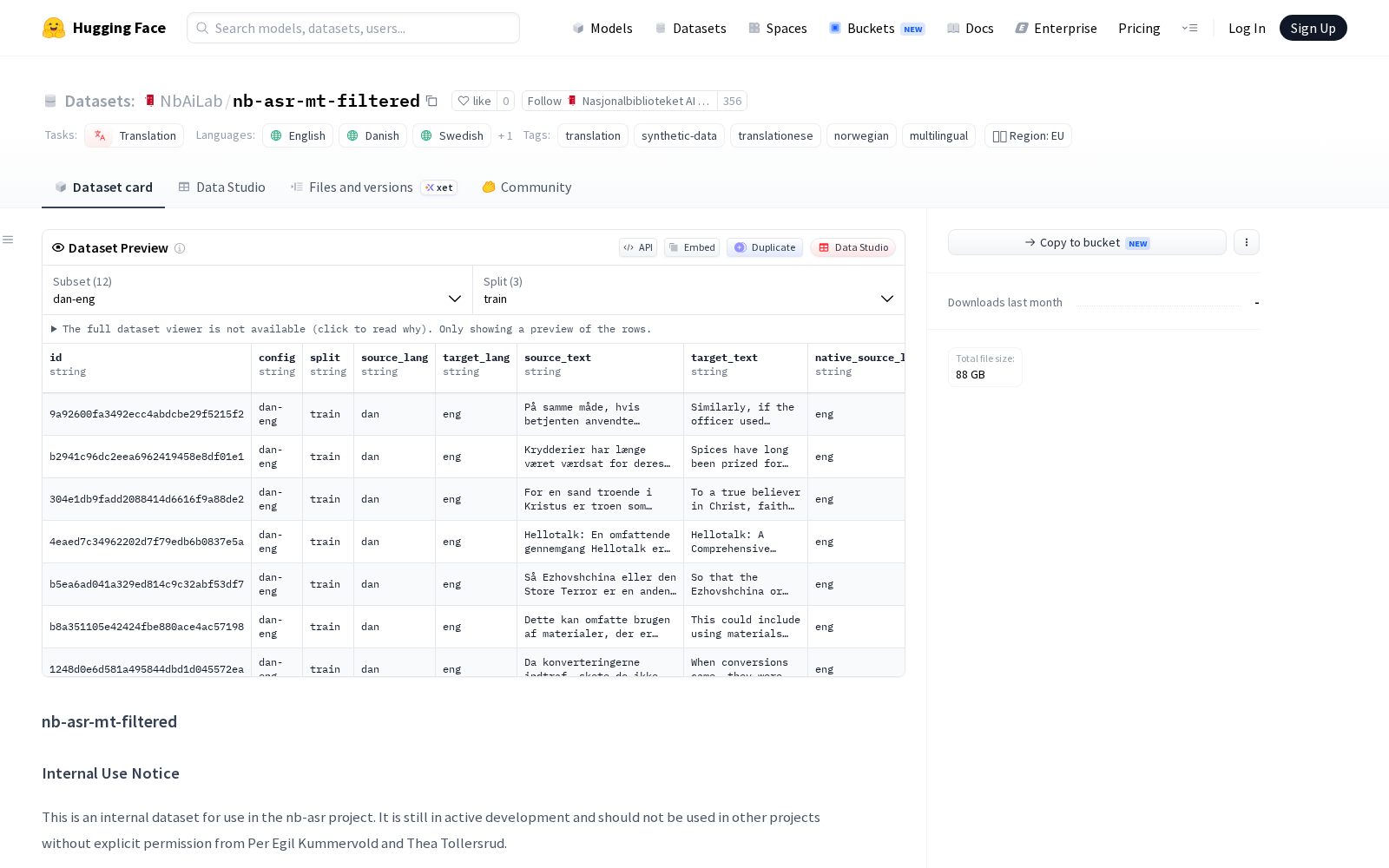
数据集单条记录包含模型ID、版本信息、验证元数据、使用元数据、时间元数据、母语原始文本、枢轴翻译文本和回译文本共8类字段,可满足研究人员对语料来源溯源、质量分层的需求。除本次发布的filtered版本外,实验室还同步推出了更严格的nb-asr-mt-gold版本,后者在母语原文与回译文之间增加了同语言嵌入相似性校验,优先保障高置信度的有用语料覆盖,而非严格的字符串完全匹配,适合对语料质量要求极高的训练场景。
目前nb-asr-mt-filtered总规模达10,814,726行,覆盖12种语言对配置,全部为英语、丹麦语、瑞典语、挪威语四大语言的双向翻译组合,其中仅英语到挪威语的语料就达1,811,476行,可充分支撑北欧区域跨语言翻译模型的训练需求,不同语言对的具体规模可参考数据集README中的详细表格。从应用价值来看,该数据集目前已明确可用于机器翻译训练、翻译腔感知数据构建两大方向,训练时使用source_text作为输入、target_text作为母语监督目标即可直接使用。除此之外,行业研究人员还可基于该数据集开展翻译腔识别算法研发、跨语言大模型本地化微调、北欧数字人文馆藏批量翻译等多类研究,其反向合成+多层过滤的语料构建思路,也可为全球其他小语种翻译数据集的研发提供参考范式。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)