

随着多模态大模型技术的快速迭代,视频类非结构化数据已经成为AI模型训练、算法落地的核心数据资源之一。但当前公开大规模视频数据集普遍存在索引体系缺失、分类逻辑模糊、预处理成本高的痛点,行业调研显示,大量视频AI研发团队需要耗费30%以上的项目周期完成视频数据的梳理、标注与定位工作,大幅拉高了视频类AI应用的研发门槛。2026年5月25日,大模型研发团队InternLM在全球最大的AI开源社区HuggingFace首发CapRL-Video-178K数据集,为行业提供了一套标准化的大规模视频数据索引解决方案。
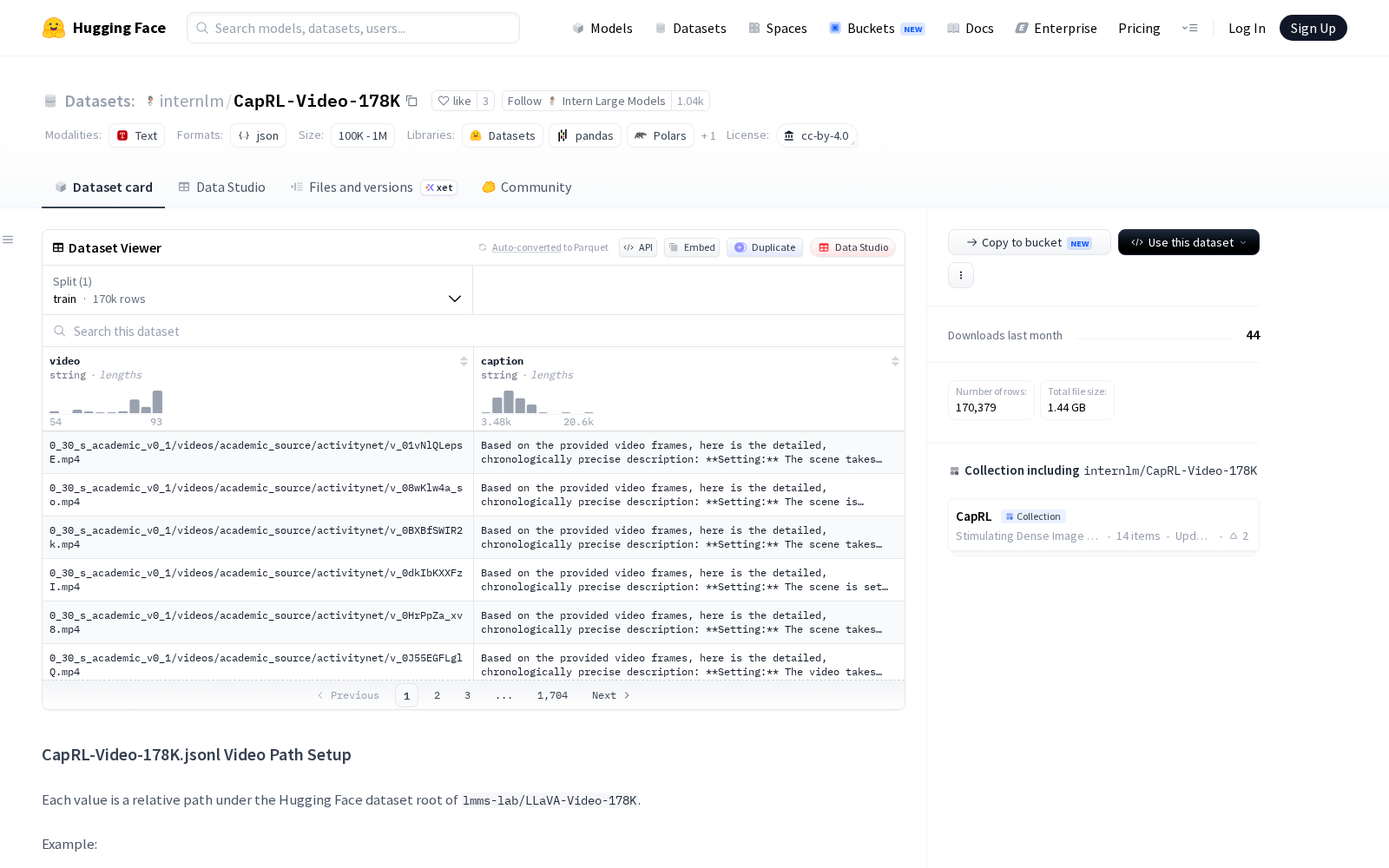
本次发布的CapRL-Video-178K核心为JSONL格式的视频路径索引文件,本身不包含实际视频资源,而是与开源视频数据集LLaVA-Video-178K做了结构化映射,用户只需从Hugging Face数据集仓库 `lmms-lab/LLaVA-Video-178K` 下载并解压原始视频文件,按照官方README提供的目录结构配置后,即可通过索引快速定位调用所需视频资源,无需自行完成数据集的分类梳理工作。
作为CapRL-Video-178K的底层资源库,LLaVA-Video-178K共包含约17.8万个MP4格式视频样本,官方按照时长区间和来源渠道两个维度将样本划分为8个子集:时长维度覆盖0-30秒、30-60秒、1-2分钟、2-3分钟四类区间,来源分为YouTube公开内容、学术标注来源两类,具体样本分布为:0_30_s_youtube_v0_1(72970个)、2_3_m_youtube_v0_1(24685个)、1_2_m_youtube_v0_1(22427个)、30_60_s_youtube_v0_1(19994个)、0_30_s_academic_v0_1(12139个)、30_60_s_academic_v0_1(10503个)、1_2_m_academic_v0_1(4572个)、2_3_m_academic_v0_1(3089个)。
这种双维度分类的索引设计,可适配不同场景的研发需求:比如短视频内容审核、智能推荐算法研发可优先调用0-30秒的短视频子集,长视频语义理解、事件脉络识别类任务可匹配1-3分钟的中长视频子集,学术类算法验证场景可优先选择标注质量更高的学术来源子集,工业界泛化性训练则可选择场景更丰富的YouTube来源子集。除了降低AI研发的数据预处理成本外,这套索引体系也可应用于企业级视频数据集的规范化管理,帮助机构快速完成存量视频资源的分类梳理与权限配置。
从数据要素市场的发展维度来看,CapRL-Video-178K的发布代表了AI训练数据供给的新趋势:区别于传统原始数据集的简单公开,经过结构化加工、场景化分类的“数据加工产品”正在成为供给侧的核心升级方向,这类产品能够大幅降低数据使用门槛,提升数据流通与利用效率,为视频多模态技术在智慧城市、智能媒体、内容安全等领域的落地提供重要的基础支撑。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)