

近年来,随着AIGC技术的快速落地,长文本语音合成、AI虚拟人对话、智能有声内容生产等语音生成类应用的市场需求持续攀升,据行业公开数据显示,2025年国内语音交互市场规模已突破千亿元,长语音生成技术成为内容生产、智慧政务、消费电子等多个领域的核心技术支撑。但长期以来,国内语音生成领域的评估基准多聚焦短语音场景,存在场景覆盖不全、评估维度单一、缺乏统一行业标准等问题,不同厂商的模型性能横向对比难度大,也制约了长语音生成技术的规模化落地。
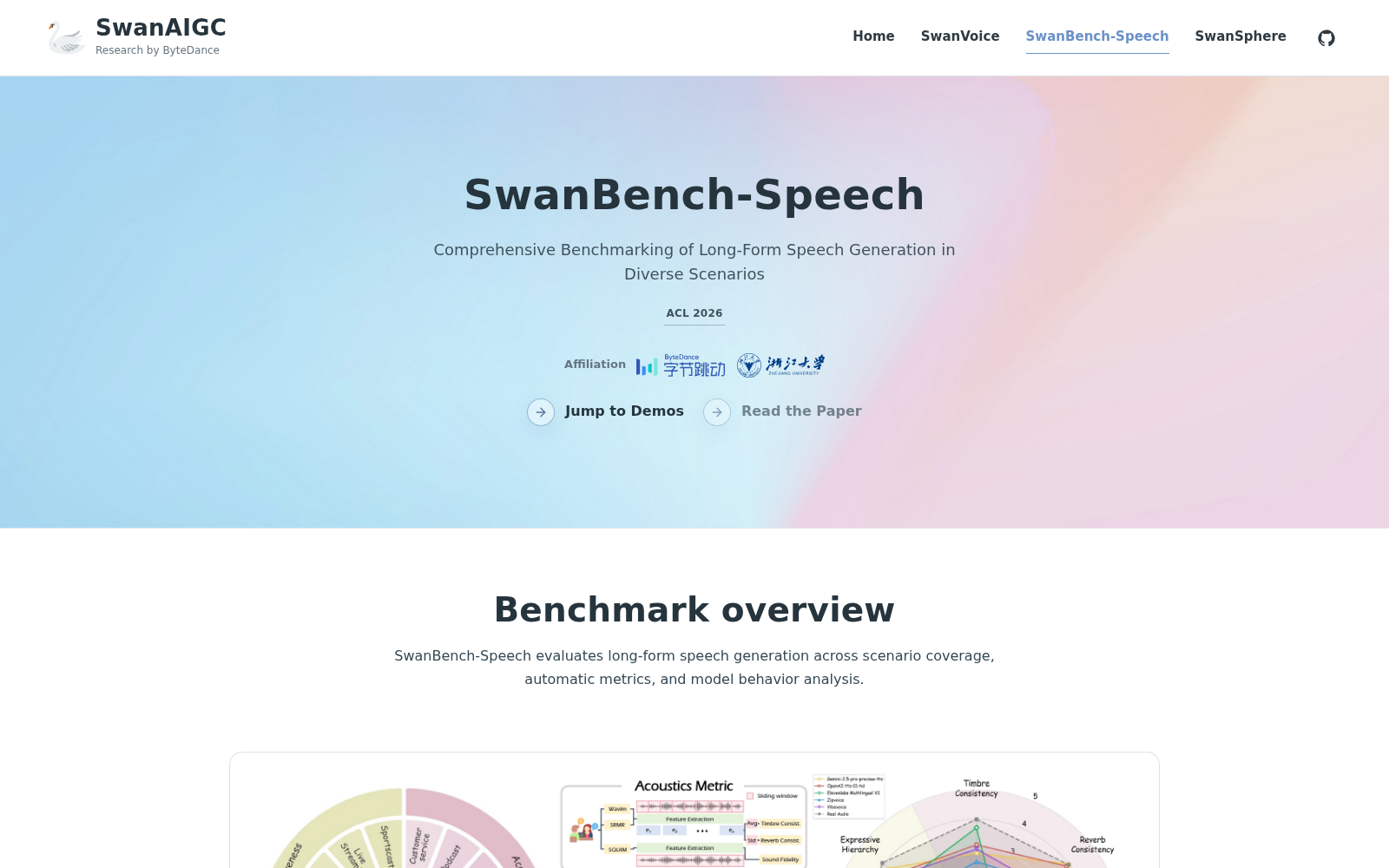
在此行业背景下,浙江大学联合字节跳动正式发布综合性长语音生成基准数据集SwanBench-Speech,该数据集于2026年5月27日首发于国际预印本平台arXiv,旨在系统评估长语音生成模型在多样化场景下的综合表现,填补行业现有评估体系的短板。据介绍,SwanBench-Speech共包含1101个经过严格筛选的测试样本,覆盖17种下游语音应用场景,针对性覆盖了长语音生成领域的声学质量、语义一致性、情感表达力三大核心技术挑战。数据集的样本来源涵盖公开在线文本语料库、正规音频媒体内容及大语言模型生成内容,所有样本均经过多重去重、多维度质量过滤及专业团队人工校验,保障了数据集的权威性、中立性与可用性。
作为国内首个覆盖多维度评估要求的长语音生成基准数据集,SwanBench-Speech主要面向长文本语音合成、对话式语音生成两大核心应用领域,可广泛应用于AI有声书生成效果测评、虚拟数字人对话连贯性校验、智能客服多轮交互表达力评估、语音大模型迭代测试等典型场景,解决了现有评估方法在场景覆盖度、跨场景一致性、情感表达力维度上的评估缺失问题,能够为各类语音生成模型的性能对比、优化迭代提供标准化、细粒度的自动化评估框架,有效降低行业内的模型评估成本,减少不同机构技术对比的标准分歧。
从数据要素市场建设的角度来看,高质量的测试基准数据集是AI技术迭代的核心基础设施,本次SwanBench-Speech的发布,填补了国内长语音生成领域标准化评估数据集的空白,也为国内AI基础数据集的规范化研发、开放共享提供了参考样本,将进一步推动我国语音生成技术的技术迭代与商业化落地,助力数字内容产业、智能交互产业的高质量发展。
详情页内容:



_1769672084863.jpg)