

作为解决大语言模型幻觉问题的主流技术路径,检索增强生成(RAG)通过外接知识库检索相关内容作为生成依据,大幅提升了大模型输出的准确性,但结构性引用失效、“已验证误导”等问题长期制约着RAG技术在专业领域的落地,行业此前也缺乏覆盖多场景、多模型的标准化引用质量评估基准。正是瞄准这一行业痛点,延世大学本次联合多机构发布了大规模引用质量评估数据集CITETRACE,旨在为检索增强大语言模型的结构性引用失效问题提供系统化的分析与评估支撑。
该数据集的样本池具备极强的场景覆盖性与代表性:共收录来自28个Stack Exchange社区的11,200条真实用户查询,覆盖技术研发、医学咨询、法律服务等多个对内容准确性要求极高的垂直领域;研究团队同步收集了来自5家技术服务商的10款主流大模型生成的112,000条响应内容,最终加工形成761,495条可直接用于评估的引用对,每一条引用对都完整关联了原始用户查询、模型生成句子以及官方爬取的源内容全量文本,确保评估样本的真实性与全链路可追溯性。为了避免评估偏差,数据构建过程采用统一中性提示词收集不同模型的响应,同时对每条引用标注的URL进行直接爬取获取原始源文本,排除了二次转载、内容篡改等可能影响评估结果的干扰因素,为后续的引用质量评估筑牢了可信基础。
从应用价值来看,CITETRACE主要面向检索增强系统的引用质量评估、“已验证误导”现象诊断两大核心场景,可从用户意图对齐、检索源内容适任性、答案保真度等多个维度定位RAG系统的失效问题,为改进检索与生成阶段的协同机制提供关键的数据资源支撑。除此之外,该数据集还可支撑多类延伸场景的探索:可为学术出版领域的引文自动校验工具研发提供训练样本,为法律、医疗等专业领域的生成式AI应用提供合规性测试基准,也可为大模型输出内容的可信度审计体系建设提供标准化参考,为生成式AI向高风险垂直领域落地筑牢可信底座。作为AI评估类垂直数据集的代表性成果,该数据集的发布也为数据要素市场中智能数据资源的细分领域供给提供了新的参考方向。
Dataset card内容:
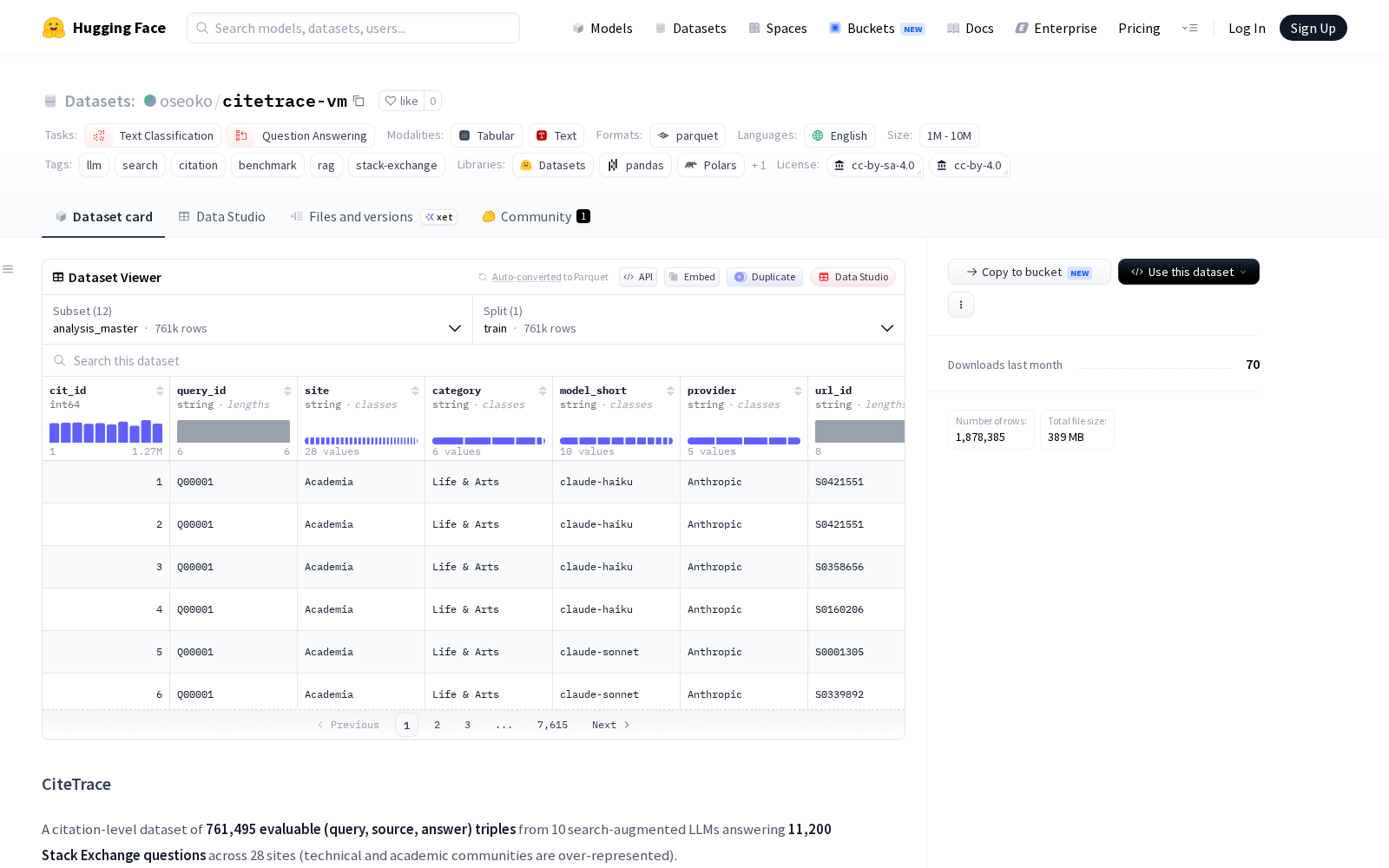
Files and versions内容:



_1769672084863.jpg)