

作为下一代人工智能的核心落地方向,具身智能近年来成为全球科技研发的重点赛道,但其发展长期受制于高质量跨模态数据集的稀缺:传统视觉语言数据集往往侧重语义信息标注,缺乏物理空间约束、时空任务逻辑等维度的监督信号,导致大模型在落地实体场景时普遍存在“能听懂指令、但做不对操作”的痛点,高级语义推理能力与低级空间物理认知的脱节,已经成为限制机器人自主任务执行效率的核心瓶颈。本次清华大学联合腾讯混元团队推出的GEM-4M,正是瞄准这一行业痛点打造的具身智能领域基础支撑资源。
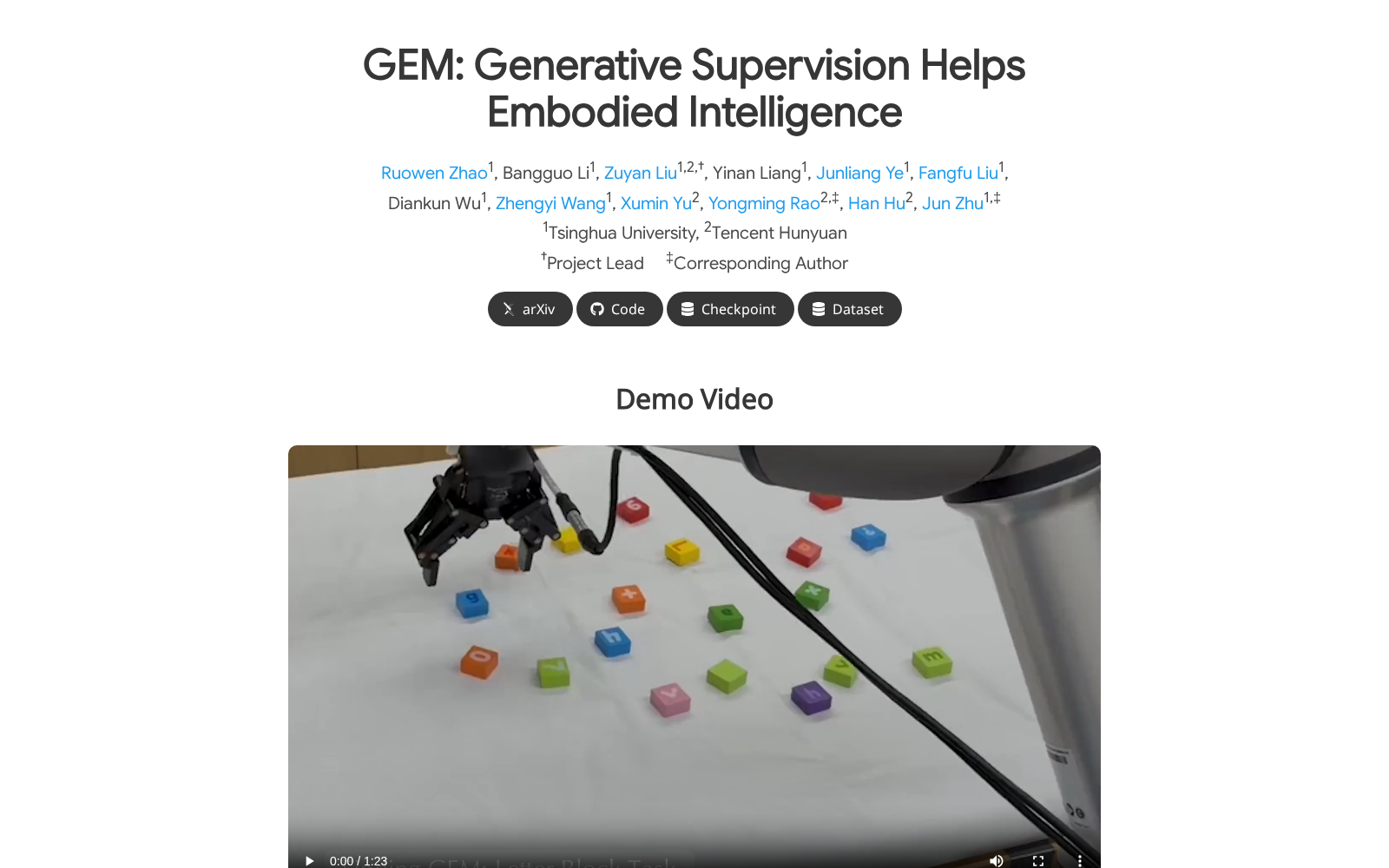
作为专门面向具身智能场景打造的预训练数据集,GEM-4M包含约400万条问答对,数据来源融合了具身任务中的基础定位、时空规划与物理推理等多模态信息,并配以高质量的深度监督信号。其构建过程通过精心设计的数据引擎整合了多样化的具身任务数据,能够针对性强化模型对场景几何结构与物理约束的理解,从数据供给端解决传统模型在高级语义推理与低级空间物理知识之间的脱节问题。
从应用价值来看,GEM-4M主要面向具身视觉语言模型、机器人任务规划两大核心领域提供数据支撑,未来可广泛应用于多个具身AI落地场景:比如家庭服务机器人可基于该数据集训练的模型,准确识别家居场景的物体属性与空间布局,完成物品收纳、老人陪护等复杂任务;工业场景下的人形机器人可依托数据集中的物理推理标注,实现高精度的元器件组装、设备巡检等操作;物流仓储领域的自主移动机器人也可借助其时空规划相关数据,优化动态避障、货物分拣的决策效率,此外该数据集还可支撑AR空间交互、数字孪生场景建模等多个数字化方向的技术迭代。
作为数据要素市场中AI基础层的核心资源,高质量垂直领域数据集的供给能力,直接决定了细分赛道的技术迭代速度。本次GEM-4M的发布,不仅填补了国内具身智能领域大规模多模态预训练数据集的供给空白,也为全球具身AI研发提供了新的基础支撑,对于推动人工智能从“数字世界交互”向“物理世界交互”的跨越,加速具身智能技术的商业化落地具有重要的行业价值。
详情页内容:



_1769672084863.jpg)