

近年来,AI for Science领域商业化进程加速,AI科研助手、智能文献分析工具、垂直领域科学大模型等产品快速落地,但行业始终缺乏标准化的评估基准,来验证大模型基于已有文献识别研究缺口、提出高质量研究问题的核心能力——这一能力正是科研工作从文献梳理走向创新立项的关键前提。近日,Deep Cognition and Language Research (DeCLaRe)实验室正式发布rq-bench基准数据集,填补了这一领域的评估空白。
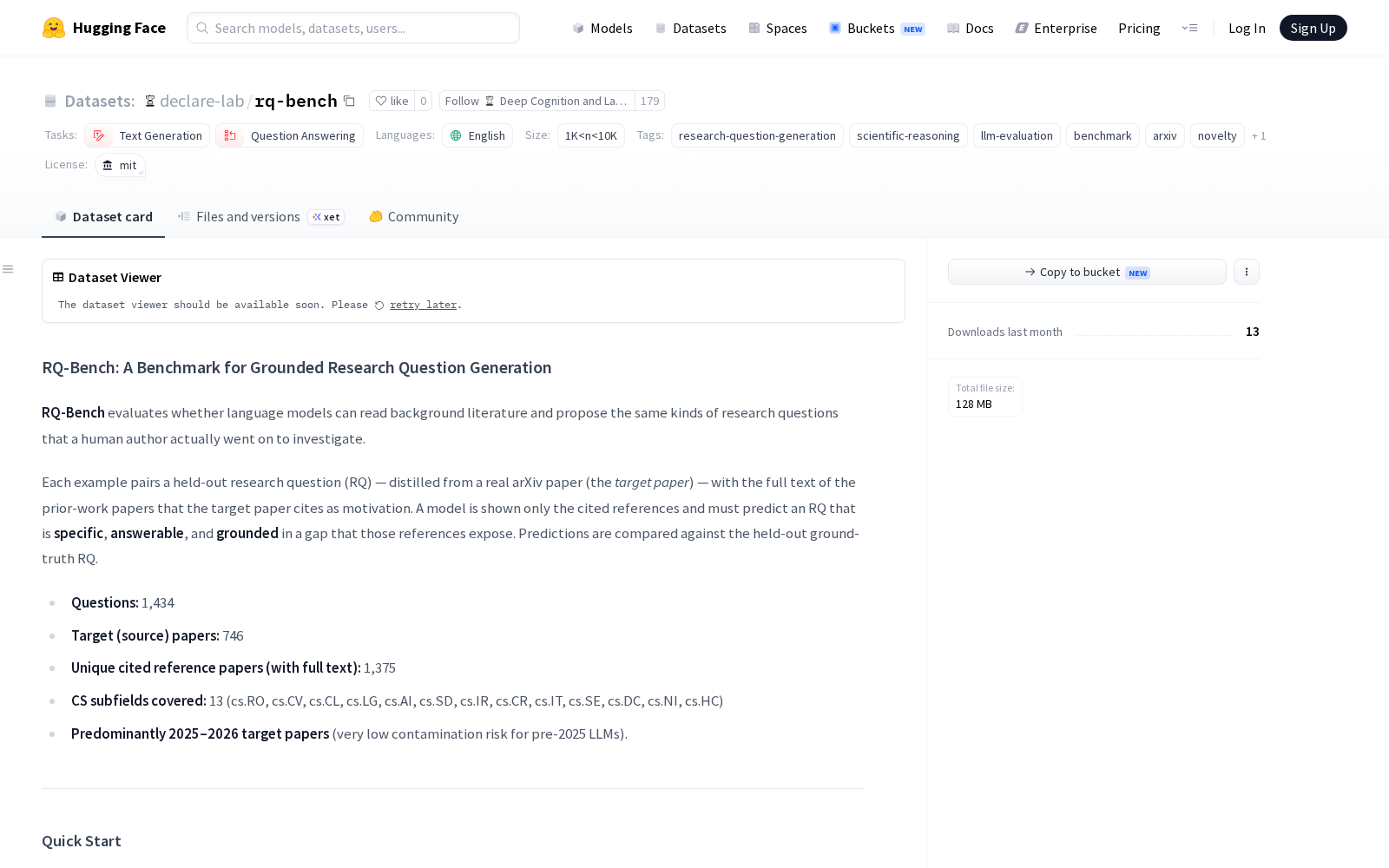
据介绍,rq-bench是专门用于评估语言模型基于背景文献提出研究问题能力的基准数据集,其核心特点是所有样本均来自真实科研场景,而非人工事后虚构。该数据集共包含1434个经过标注的研究问题,全部基于746篇2025-2026年发表的arXiv真实论文的动机、贡献框架提取而来,大幅降低了预训练语言模型因预训练语料覆盖相关内容导致的数据污染风险,测评结果可信度更高。所有研究问题均与目标论文引用的参考文献全文配对,要求测试模型仅依托参考文献内容,预测出具体、可回答、且符合文献暴露的研究差距的问题,再与真实研究问题做对标评估。
从数据集架构来看,rq-bench主要由两部分构成:一是rq_dataset.jsonl文件,包含所有研究问题记录及其配套元数据,每条记录涵盖唯一标识符、问题文本、源论文标题、所属子领域、新颖性类型、核心研究思路、问题陈述,以及基于引用文献的差距分析信息;二是cited_papers/目录,包含1375篇被引参考文献的全文内容,且按论文章节结构组织,方便不同测评场景调用。目前数据集覆盖计算机科学领域下的机器人(cs.RO)、计算机视觉(cs.CV)、自然语言处理(cs.CL)等13个细分方向,可满足不同垂直领域科学大模型的评估需求。
作为面向科研场景的专用基准数据集,rq-bench的应用空间十分广阔:首先可用于科学类大模型的基准测试,客观评估其研究问题生成、科学构思、基于文献的逻辑推理能力,为大模型的迭代优化提供量化参考;其次可作为训练数据,用于AI科研助手的微调与偏好学习,提升工具输出研究问题的合规性、可行性与创新度;此外还可支撑科研情报领域的文献差距分析工具研发,帮助科研人员快速梳理细分领域的研究空白,缩短科研立项的前期调研周期。
研发团队同时披露了数据集当前的局限性:目前rq-bench仅覆盖计算机科学领域,目标论文时间集中于近两年,被引论文的章节结构存在一定差异,且研究问题是通过大语言模型辅助流程从论文框架中提取,并非由论文作者直接提交,后续版本将逐步优化上述问题。行业人士指出,rq-bench的发布进一步完善了科学AI领域的评估体系,也为垂直领域基准数据集的构建提供了参考样本,对推动AI for Science场景的标准化、规范化发展具有重要意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)