

随着蛋白质语言模型(如Meta开源的ESM系列模型)、AI蛋白结构预测技术的快速迭代,标注化的高质量蛋白序列数据集已经成为生命科学、合成生物学、生物材料研发领域的核心生产要素。针对当前结构蛋白家族分类研究缺乏统一标注训练集的行业痛点,麻省理工学院(MIT)原子与分子力学实验室(Laboratory for Atomistic and Molecular Mechanics,简称LAMM)正式公开发布structural-protein-families专用数据集,该数据集于2026年5月29日率先上线HuggingFace平台,面向全球科研人员开放使用。
作为全球顶尖的分子尺度力学研究机构,MIT LAMM长期聚焦生物材料、软物质的分子结构与宏观性能关联研究,在蜘蛛丝、胶原蛋白等天然结构蛋白的性能解析、人工合成方向积累了大量研究成果,本次发布的数据集正是该实验室在蛋白序列分类研究方向的公开沉淀,核心目标是降低相关领域的科研数据获取门槛。
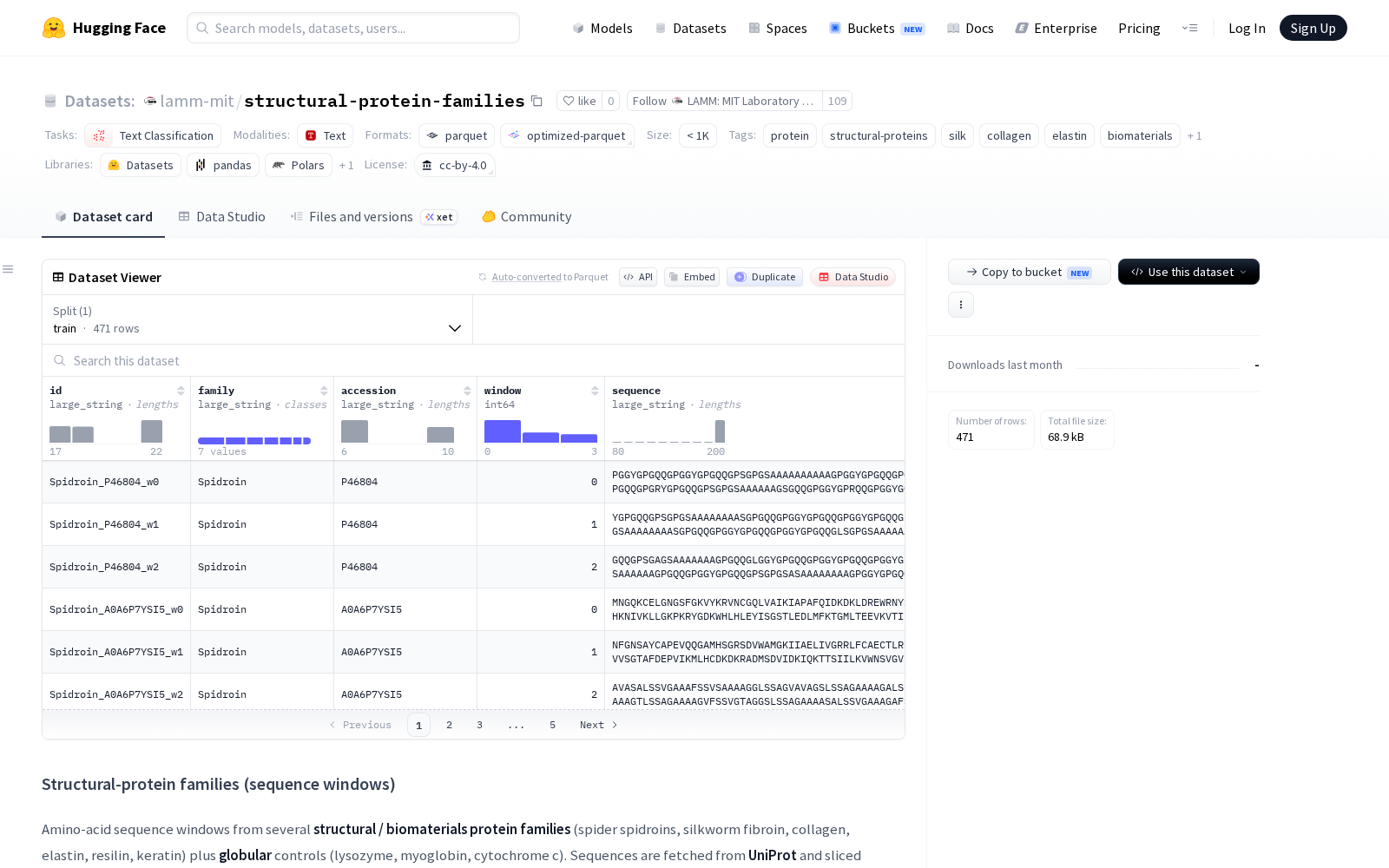
据介绍,本次发布的structural-protein-families数据集覆盖了多个核心结构/生物材料蛋白家族,包括具备高强度特性的蜘蛛丝蛋白、蚕丝丝蛋白,与人体组织修复高度相关的胶原蛋白、弹性蛋白、角蛋白,以及节肢弹性蛋白等特色结构蛋白,同时纳入了溶菌酶、肌红蛋白、细胞色素c等球状蛋白作为对照组样本,样本覆盖范围兼顾了科研需求的多样性与典型性。所有序列均提取自全球权威的蛋白质序列数据库UniProt,按照统一规则切割为重叠的固定长度窗口,每一行数据对应一个序列窗口,并附带明确的蛋白质家族类别标签,可直接用于分类模型训练。
该数据集专为蛋白质序列迁移学习场景设计,核心定位是支撑科研人员基于预训练蛋白质语言模型生成的冻结嵌入,训练轻量级分类头快速完成蛋白质序列窗口的家族归属预测。数据集包含5个核心字段:由家族标签、UniProt登录号和窗口索引组成的唯一标识符id、蛋白质家族类别标签family、源蛋白质在UniProt中的登录号accession、窗口在源蛋白质序列中的索引位置window、长度不超过200个残基的氨基酸序列字符串sequence。序列窗口按照统一规则生成:单窗口长度为200个氨基酸,滑动步长为150个氨基酸,每个源蛋白质最多提取4个窗口,样本分布均衡可控,避免了数据偏差对模型训练的干扰。
从应用价值来看,该数据集除了可直接支撑蛋白质家族分类、蛋白质序列分析等基础研究任务外,还可广泛应用于多个前沿领域:在生物材料研发场景中,科研人员可基于该数据集训练分类模型,快速筛选具备特定性能潜力的结构蛋白突变序列,加快人工蜘蛛丝、医用胶原蛋白等高附加值生物材料的研发效率;在合成生物学场景中,该数据集可作为基准测试集,验证不同蛋白质工程改造方案的家族归属匹配度,降低合成蛋白的功能验证成本;在AI生命科学研究场景中,该数据集可用于蛋白质语言模型的微调效果验证、小样本学习算法性能测试等,填补了结构蛋白细分领域标注数据集的空白,对推动数据驱动的生命科学研究有着重要的基础设施价值。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)