

当前大语言模型的能力迭代已经从通用语义理解转向复杂任务的深度推理能力突破,推理轨迹数据作为训练模型思维链能力、结构化分析能力的核心素材,其质量直接决定了大模型在数学求解、逻辑推演、代码调试、复杂决策等场景的落地效果,尤其是在强化学习前的监督微调冷启动阶段,高质量、长链条的推理演示数据一直是行业稀缺资源。近日,MLX Community正式对外发布的JOSIE-Zero-8B-Reasoning-Traces-N67,正是瞄准这一行业需求推出的高质量合成推理轨迹数据集,专为训练具备高阶推理能力的语言模型设计。
该数据集由JOSIE-ZERO-8B模型生成,生成过程依托MLX-LM-LoRA框架的GRPO(组相对策略优化)训练流程完成优化,配套的自定义奖励函数专门针对显式推理输出、思维链式问题拆解、自我纠错、结构化分析等行为做了权重倾斜,从生成源头保障了推理轨迹的规范性和参考价值。
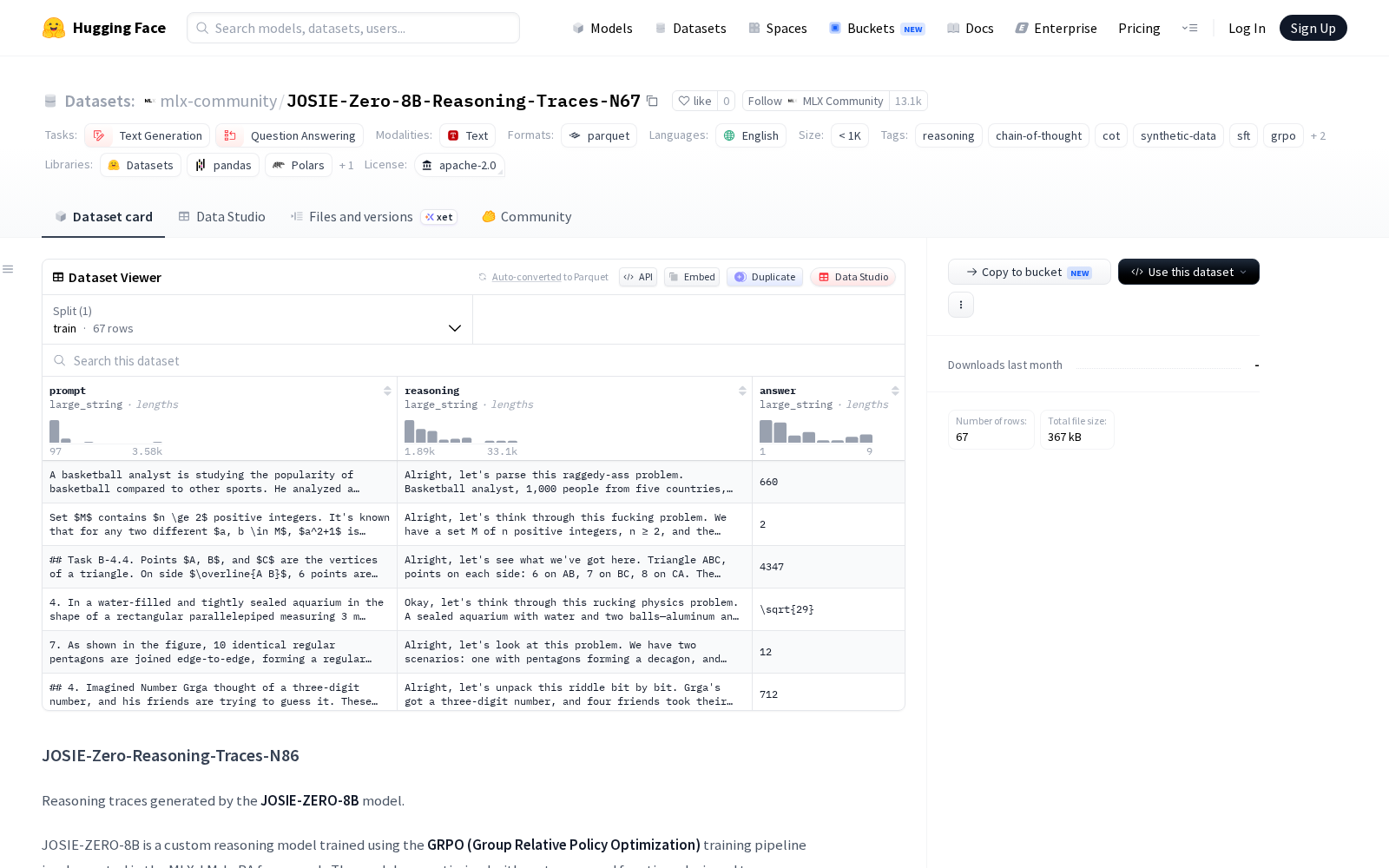
公开参数显示,该数据集共包含67个样本,所有样本均以JSON格式存储,单样本结构覆盖提示(prompt)、完整推理过程(reasoning)、最终答案(answer)三个核心模块,其中推理过程完整还原了模型从接收问题到输出答案的全链路多步分析链条,没有做截断或精简处理。规模维度,数据集总令牌数达234183,其中推理相关令牌数为226271,占比超96%;单样本平均令牌数达3443,最长推理链令牌数超过11000,整体呈现典型的长形式、高细节度推理演示特征。
在适用场景上,该数据集首先针对大模型推理训练的冷启动监督微调(SFT)场景设计,可在推理模型进入GRPO、PPO、DPO、RLHF等强化学习训练阶段前,为模型提供规范的推理行为示范,帮助模型快速形成结构化推理的基础能力。除此之外,该数据集还可用于三大方向:一是将大模型的推理能力蒸馏到参数量更小的端侧模型,降低推理能力落地的硬件门槛;二是用于长思维链训练,提升模型处理多步骤复杂任务的能力;三是作为研究素材,支持学术界开展推理涌现机制、长上下文行为特性、推理令牌效率、强化学习生成推理轨迹效果等方向的前沿研究。官方同时提示,由于数据集推理链长度普遍较长,建议开发者使用上下文窗口不低于16k(推荐32k及以上)的模型开展训练。
官方同时提示,该数据集的所有推理轨迹均为合成生成,不同样本的推理质量存在差异,且不保证所有内容的事实正确性;同时67个样本的规模相对有限,更适合作为推理引导类资源使用,无法替代全量指令微调数据集。从行业价值来看,该数据集的发布填补了当前长形式、高完整度推理轨迹训练资源的缺口,无论是对产业界优化大模型推理能力、落地复杂场景需求,还是对学术界开展大模型推理机制的基础研究,都具备较高的参考价值。
查看JOSIE-Zero-8B-Reasoning-Traces-N67
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)