

当前,AI for Science(人工智能驱动科学研究)已成为全球科技前沿赛道,其中AI与基础数学的融合更是被视为推动数理研究效率突破、实现自动定理证明、数学生成式应用的核心方向。但长期以来,该领域的训练数据一直存在两类割裂问题:一类是基于学术论文的非形式化文本数据,缺乏严谨的形式逻辑校验;另一类是形式定理库数据,缺乏真实科研语境的关联支撑,两类数据的对齐缺口直接限制了AI数学生成类模型的性能上限。2026年5月29日,耶路撒冷希伯来大学研究团队在预印本平台arXiv首发的COMPOSE大规模数学研究数据集,正是瞄准这一行业痛点打造的基础资源。
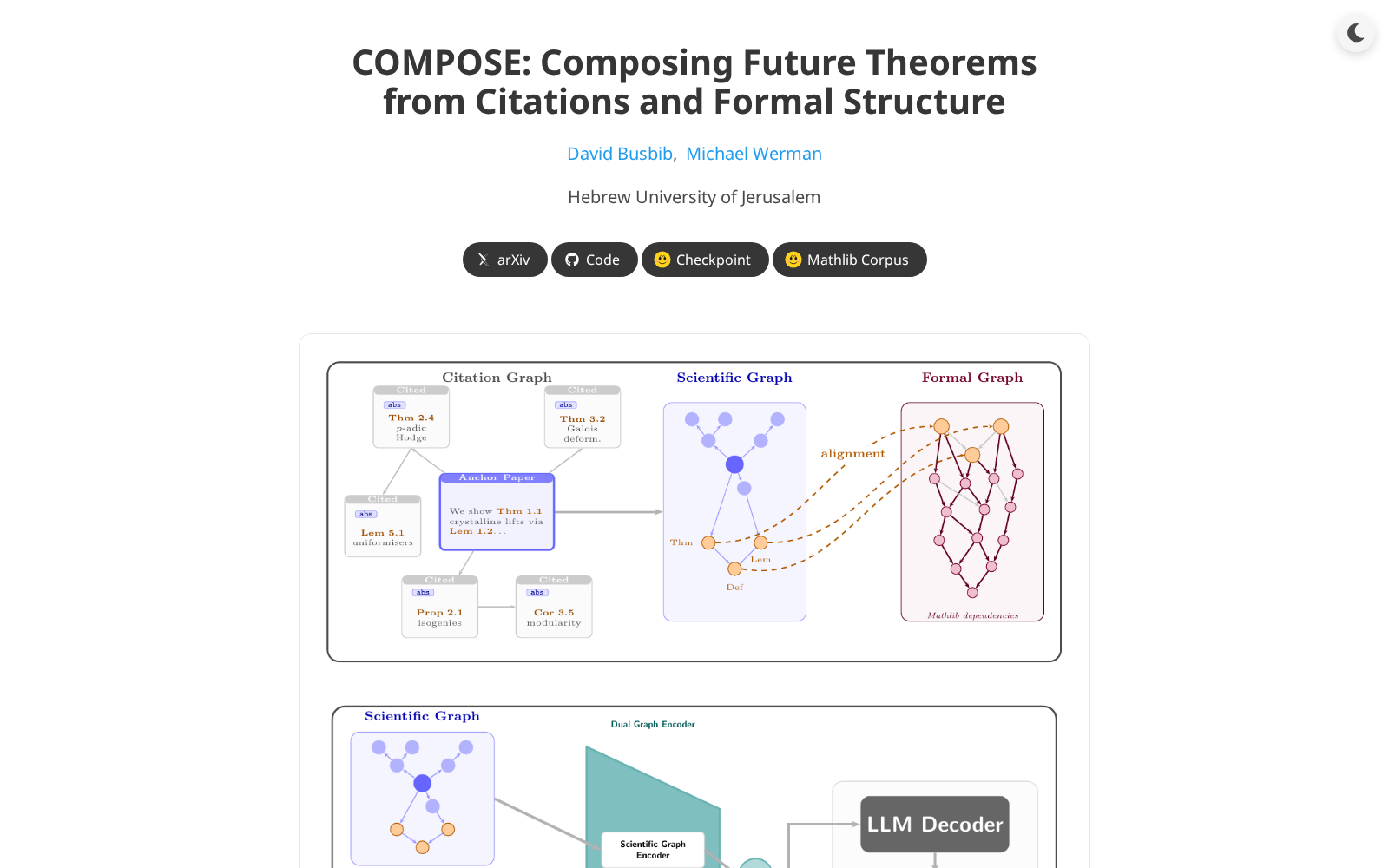
据介绍,COMPOSE数据集是面向接地式未来数学生成任务打造的专用训练资源,核心支撑基于科学引文和形式定理依赖的数学生成研究。整个数据集包含108000个配对样本,采用独特的双图结构设计:其中科学图基于arXiv平台收录的数学论文引文网络、定理提取结果构建,形式图则基于开源Mathlib定理库的依赖结构构建,两类图结构一一对应完成配对。数据集的原始来源覆盖2000年至2023年发布的50万篇数学学术论文,所有样本均通过FrenzyMath工具完成非形式化内容对齐处理。整个数据集的构建流程遵循严谨的科研规范:先从S2ORC学术文献库中筛选收录数学领域论文,构建完整的引文关联网络,再从中提取标注定理节点,最终与Mathlib形式定理库的内容完成匹配映射,最终形成同时覆盖科研语境与形式逻辑的双结构数据集。
从应用方向来看,COMPOSE数据集当前主要面向人工智能驱动的数学研究预测领域,核心解决“如何结合科学研究语境与形式逻辑约束生成合理未来数学命题”的行业共性问题,可为机器学习模型提供多源知识融合的训练基础。除了官方提及的数学命题生成、形式定理依赖分析两大方向外,该数据集未来还可拓展应用于多个相关场景:例如为自动定理证明大模型提供跨语境的预训练数据支撑,提升模型在真实科研场景下的推理准确率;基于引文与定理依赖的双维度关联,可用于数学领域研究趋势预判,辅助科研人员识别潜在的前沿研究方向;还可应用于数学教育领域,为个性化习题生成、知识点关联图谱构建提供数据支撑。
作为当前为数不多的完成“非形式化科研文本-形式化定理”对齐的大规模公开数据集,COMPOSE的发布填补了AI+数学研究领域的细分数据空白,对于推动生成式AI在基础研究领域的落地、加快数据要素支撑科研创新的进程具有重要参考价值,也为全球开放科学资源的共建共享提供了新的样本。
详情页内容:



_1769672084863.jpg)