

随着多模态大模型技术的快速迭代,视频智能生成、VR/AR实时交互、影视自动化拟音等场景对音频内容的真实性、逻辑一致性要求持续提升。但过往行业内针对跨模态音频生成模型的评测多聚焦听觉层面的“听感相似”,缺乏对声音与物理事件因果匹配度的校验标准,常出现“敲击塑料发出金属声”“物体落地动作与声响时间错位”等逻辑漏洞,直接制约了多模态生成技术的商业化落地进程。
当地时间2026年5月29日,加州大学伯克利分校联合英伟达、华盛顿大学在预印本平台arXiv首发FlatSounds数据集,作为全球首个面向视频到音频生成的物理基准测试数据集,其核心定位是评估生成模型对物理过程的因果理解能力,而非仅判断输出结果的表面合理性,为行业提供了衡量视频到音频模型物理正确性、时间对齐性的系统化测试框架。
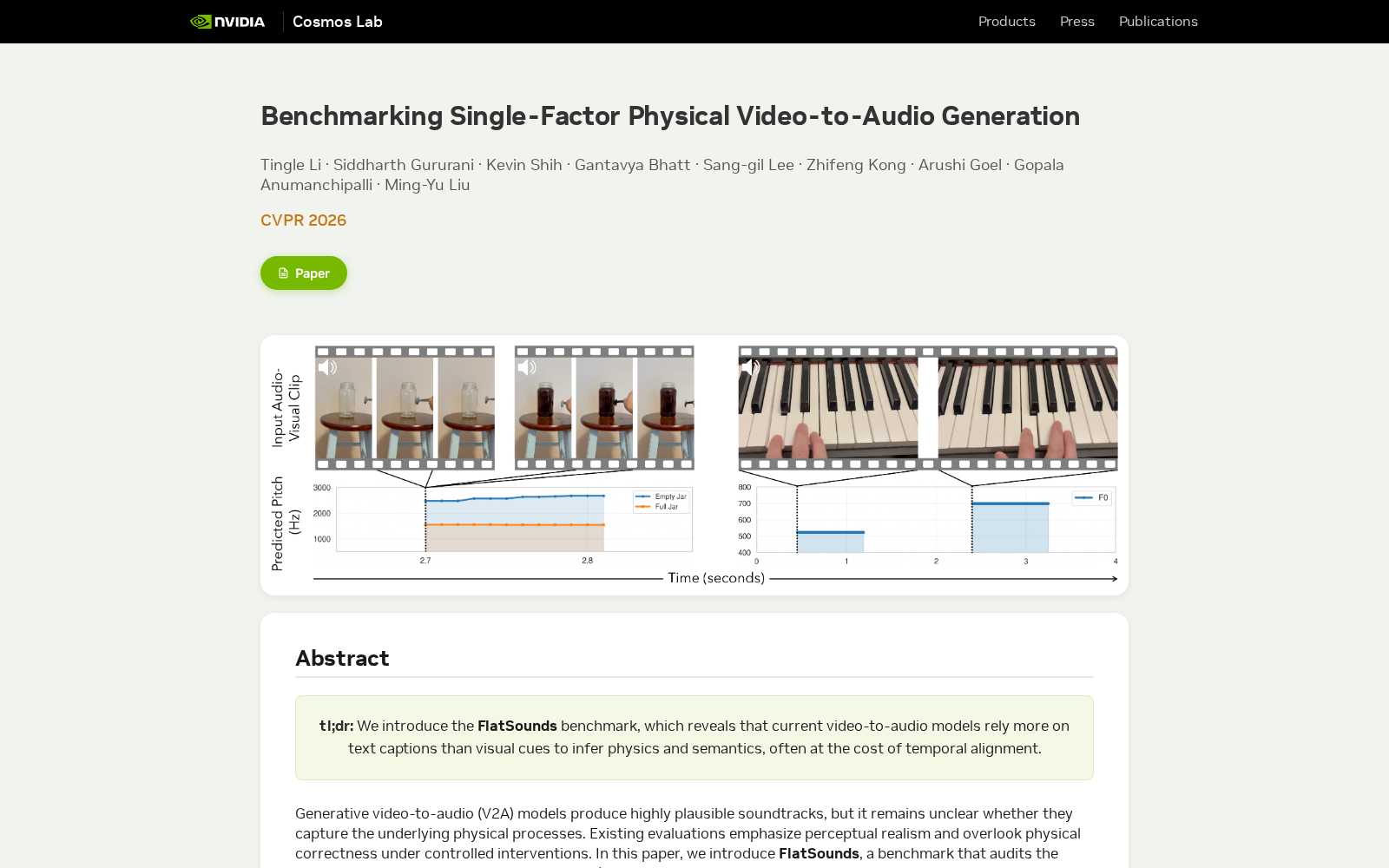
据官方披露信息,本次发布的FlatSounds数据集共包含185条精心录制的室内视频片段,单条时长为5至10秒,全部聚焦于日常物体交互产生的高能量声音事件。所有样本均通过标准化的智能手机采集流程获得,覆盖了材料属性、物体几何形状、录制环境声学特征等多种物理因素的受控变化,同时配套提供了人工标注的声音事件时间戳与场景文本描述,可支撑不同维度的模型效果校验。
从应用价值来看,该数据集未来可广泛落地于物理音频生成、视频音频跨模态生成两大核心领域的模型训练与评测环节:在影视、短视频的智能拟音场景中,经过该数据集校验的模型可实现动作、物体属性与声音的精准匹配,大幅降低后期人工校验成本;在VR/AR交互场景中,可提升用户触碰、移动物体时的音频反馈真实感,优化虚拟场景沉浸体验;在智能安防、工业巡检场景中,基于该数据集优化的跨模态模型可通过视觉画面匹配对应声响特征,辅助识别碰撞、坠落等异常事件。
作为AI大模型迭代的核心基础设施,高质量垂直基准数据集的供给一直是制约细分领域技术突破的核心瓶颈,本次FlatSounds数据集的发布,填补了跨模态音频生成领域物理一致性评测的标准空白,将推动多模态音频生成技术从“满足听感需求”向“符合真实物理逻辑”升级,为相关技术的规模化落地提供重要的数据支撑。
详情页内容:



_1769672084863.jpg)