

当前大语言模型的能力迭代高度依赖强化学习对齐环节,而高质量、标准化的专家轨迹训练数据始终是制约相关研究与落地的核心瓶颈之一——传统的专家轨迹数据往往存在格式不统一、语义冗余信息多、奖励信号匹配度低等问题,开发者需要花费大量时间做数据清洗与标注,也容易导致训练结果出现不可控的偏差。针对这一行业痛点,MIT HAN Lab正式发布SMEPO(Semantic Masked Expert Policy Optimization)专用数据集,该数据集率先上线HuggingFace,主要面向强化学习文本生成、专家轨迹掩码优化两大核心方向提供训练支撑。
据介绍,SMEPO数据集是为该团队最新论文《Hide to Guide: Learning via Semantic Masking》及配套的SMEPO强化学习方法量身打造的训练底座。SMEPO方法本身是一种创新的专家指导型强化学习方案,核心逻辑是通过掩码专家轨迹中与奖励直接相关的语义片段,同时完整保留专家决策的过程结构,避免模型直接“抄袭”专家结果,而是学习底层决策逻辑,从而大幅提升语言模型的泛化能力与决策稳定性。
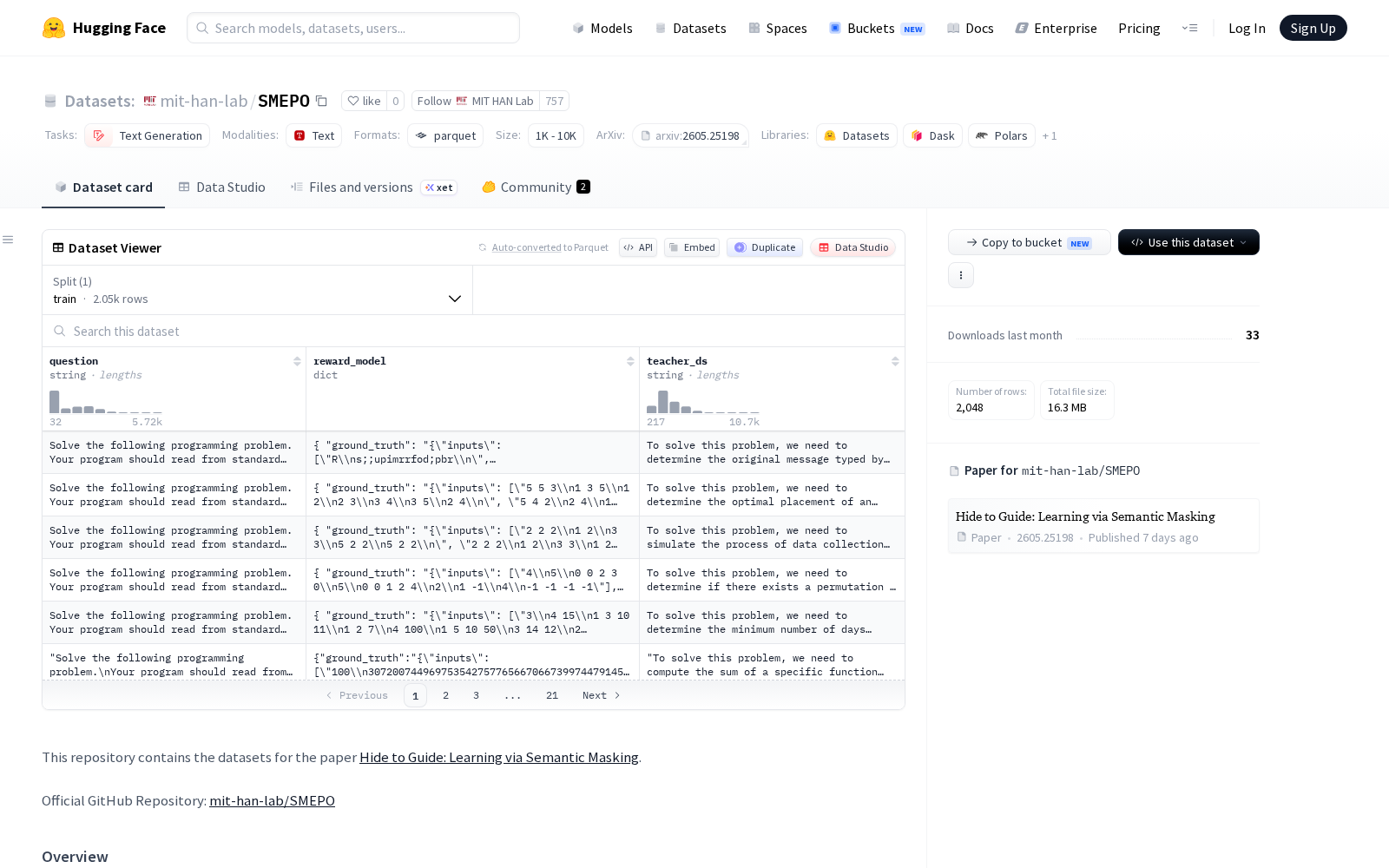
本次发布的SMEPO数据集覆盖数学推理、代码生成、智能体搜索三大当前强化学习文本生成的核心落地场景的原始专家轨迹,所有数据采用统一的结构化范式,包含三个核心字段:一是question字段,对应输入问题或任务描述,保证训练任务的一致性与可复现性;二是reward_model字段,内置验证器或奖励模型信号信息,可直接对接强化学习训练的奖励对齐环节,省去开发者额外的奖励信号标注成本;三是teacher_ds字段,存储任务特定的专家轨迹全流程,完整保留专家的决策链路与逻辑细节。
从应用场景来看,SMEPO数据集的价值覆盖科研与产业两端:在科研侧,强化学习文本生成、专家轨迹掩码优化方向的研究者可直接调用该数据集,通过官方提供的脚本从原始专家轨迹快速构建掩码版本的训练集,既可复现SMEPO方法的实验结果,也可基于该标准化基准验证自主研发的改进算法,大幅降低研究的前期数据准备成本;在产业侧,布局代码生成模型、数学推理大模型、AI智能体的科技企业,可将SMEPO数据集作为RL对齐阶段的预训练数据或效果评测基准,减少自行采集、标注专家轨迹的投入,也能避免因私有数据格式不统一、质量参差不齐导致的训练效果波动。从数据要素行业的角度来看,本次SMEPO数据集的发布,也代表了AI训练数据集正在从通用化向垂直细分场景的精细化、标准化方向发展,为垂直领域训练数据的供给提供了可参考的范式,对推动强化学习技术的落地与数据要素市场的专业化发展都具有积极意义。
MIT HAN Lab本次发布的数据集SMEPO,为论文《Hide to Guide: Learning via Semantic Masking》及SMEPO方法提供支持。数据集主要用于文本生成任务,用户可通过提供的脚本从原始专家轨迹构建掩码版本的数据集,以支持SMEPO方法的实验与应用。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)