

当前合成生物学与高性能生物材料已成为全球科技竞争的核心赛道,蜘蛛丝等天然蛋白纤维因具备高强度、高韧性、生物可降解等优势,在医用植入材料、航空航天轻量化结构、柔性电子基材等领域拥有广阔应用前景,但天然纤维产量极低、人工合成设计长期依赖试错模式,高质量标注数据集的缺失成为制约数据驱动型生物材料研发的核心瓶颈。作为全球顶尖的分子尺度力学研究机构,MIT原子与分子力学实验室(LAMM)长期聚焦生物大分子结构与功能关联、先进材料力学性能模拟方向的研究,此次发布的silkome-full-idv-grouped数据集正是针对丝蛋白研发痛点推出的标准化训练资源。
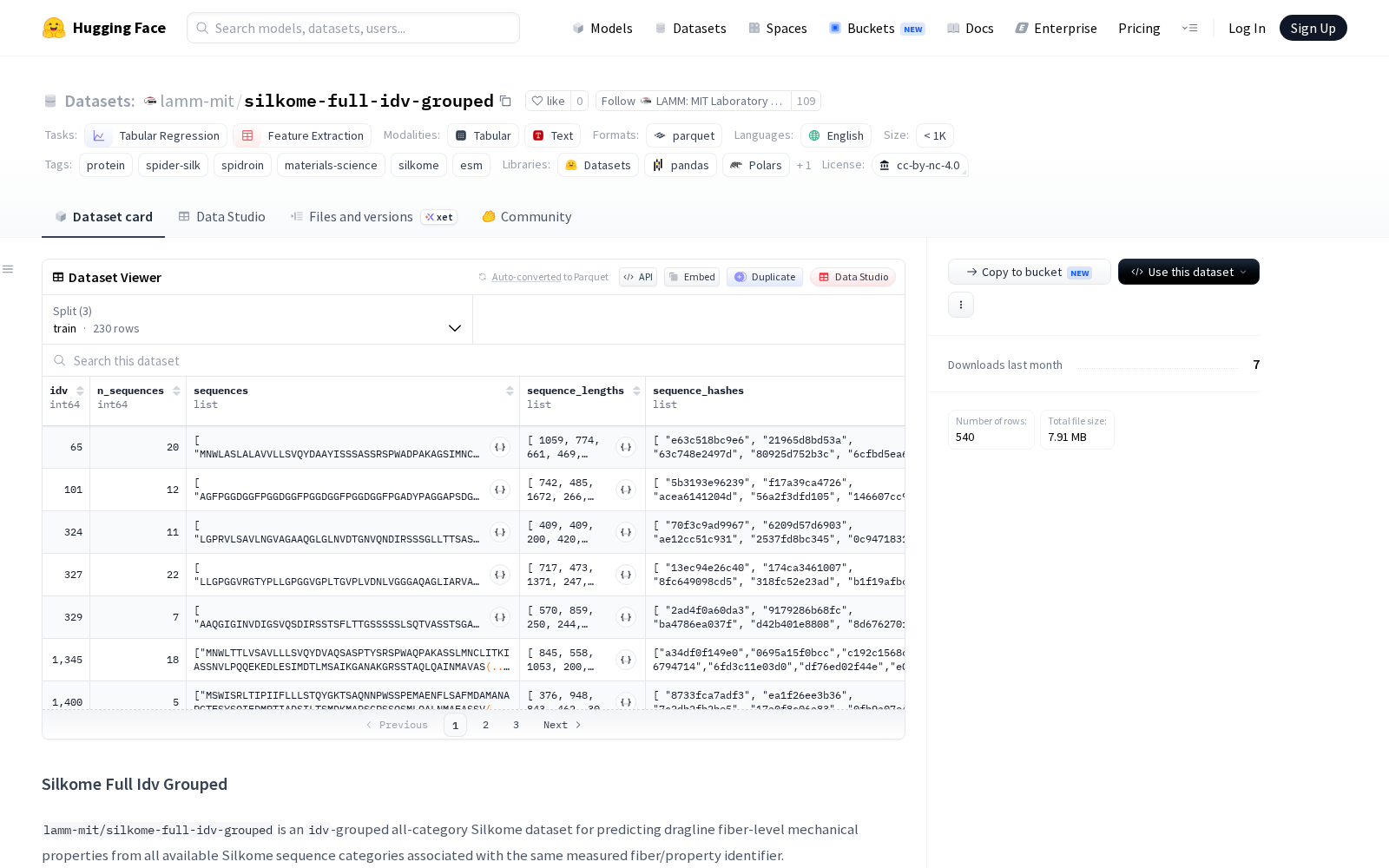
Silkome Full Idv Grouped是一个用于从丝蛋白组(Silkome)序列预测蜘蛛丝牵引丝纤维机械性能的分组数据集。该数据集由原始silkome-full数据集重构而来,核心创新在于将共享相同测量纤维/属性标识符(idv)的所有可用丝蛋白序列行聚合为单个样本,形成「序列集合-机械性能」的映射关系,旨在服务于基于ESMC等嵌入模型和后续集合级聚合模型的预测流程,解决了传统单序列数据集无法匹配天然纤维多蛋白组合真实构成的问题。
数据集包含270个唯一的idv分组样本,总计代表3563条蛋白质序列行。每个分组样本包含一个idv对应的所有丝蛋白氨基酸序列列表(sequences)、每条序列的类别标签(如MaSp1, MaSp2等,共18个类别)、序列长度以及基于类别的组成特征。目标变量是纤维级的四个关键机械性能:韧性(toughness)、杨氏模量(E)、强度(strength)和应变(strain),同时提供了这些性能的标准差及归一化版本。数据还附带了丰富的元数据,包括物种分类学信息(科、属、种)、性别、NCBI标识符等,可支撑多维度的关联研究。
为保障模型训练的严谨性,数据集已预先划分为训练集(230个样本)和测试集(40个样本),采用基于property_tuple_key的确定性分组分割方法,确保训练集和测试集在idv和四元组属性上均无重叠,从根源上避免数据泄漏问题,可实现更可靠的模型效果评估。
从应用场景来看,该数据集首先可用于纤维级机械性能预测研究,研究人员可基于该数据集训练集合级AI模型,突破传统单序列预测的准确率瓶颈,更精准地推导蛋白组合与力学性能的关联规律;其次可作为序列嵌入与集合聚合模型的通用基准测试集,推动相关AI算法的迭代优化;此外还可支撑丝蛋白类别组成分析、物种进化与序列-性能关系研究等方向的工作,为人工合成高性能蛋白纤维的分子设计提供数据支撑。需要注意的是,目标性能是纤维水平的测量值,并非单个蛋白质的直接功能标签,纤维力学还受纺丝工艺、环境参数等多种非序列因素影响,研究人员落地应用时可结合场景参数补充调整模型输入维度。
作为生命科学领域的高质量标注数据资产,该数据集的发布填补了丝蛋白集合级建模训练数据的空白,将有效降低相关研究的数据集构建门槛,推动生物材料研发从传统试错模式向数据驱动的AI预测模式转型,对加速高性能生物材料的商业化落地、完善合成生物学领域数据要素供给体系均有重要意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)