

近年来,随着AI for Science与合成生物学的交叉融合,高性能生物仿生材料的研发进程大幅提速,其中蜘蛛丝因兼具高强度、高韧性、生物相容性与可降解性,成为医疗耗材、航空航天、环保纺织等领域的热门研发方向。但由于天然蜘蛛拖丝的力学性能由多种主要壶腹丝蛋白(MaSp)的序列组合共同决定,过往基于单序列-单性能标签的数据集难以支撑更贴合真实生物合成逻辑的模型训练,行业亟需标准化的多序列集合对应宏观纤维性能的基准数据集。2026年5月30日,麻省理工学院原子与分子力学实验室(MIT LAMM)正式在Hugging Face首发silkome-masp-idv-grouped数据集,填补了这一领域的空白。
该数据集衍生自LAMM此前发布的lamm-mit/silkome-masp源数据集,核心创新在于突破了传统单序列对应单标签的数据集构建逻辑,将具有相同测量纤维/属性标识符(idv)的多个MaSp蛋白序列行分组为一个样本,形成“某个idv对应的MaSp序列集合 -> 韧性、杨氏模量、强度、应变”的映射关系,这一设计专门适配ESMC嵌入模型及后续的集合级聚合模型的训练需求。
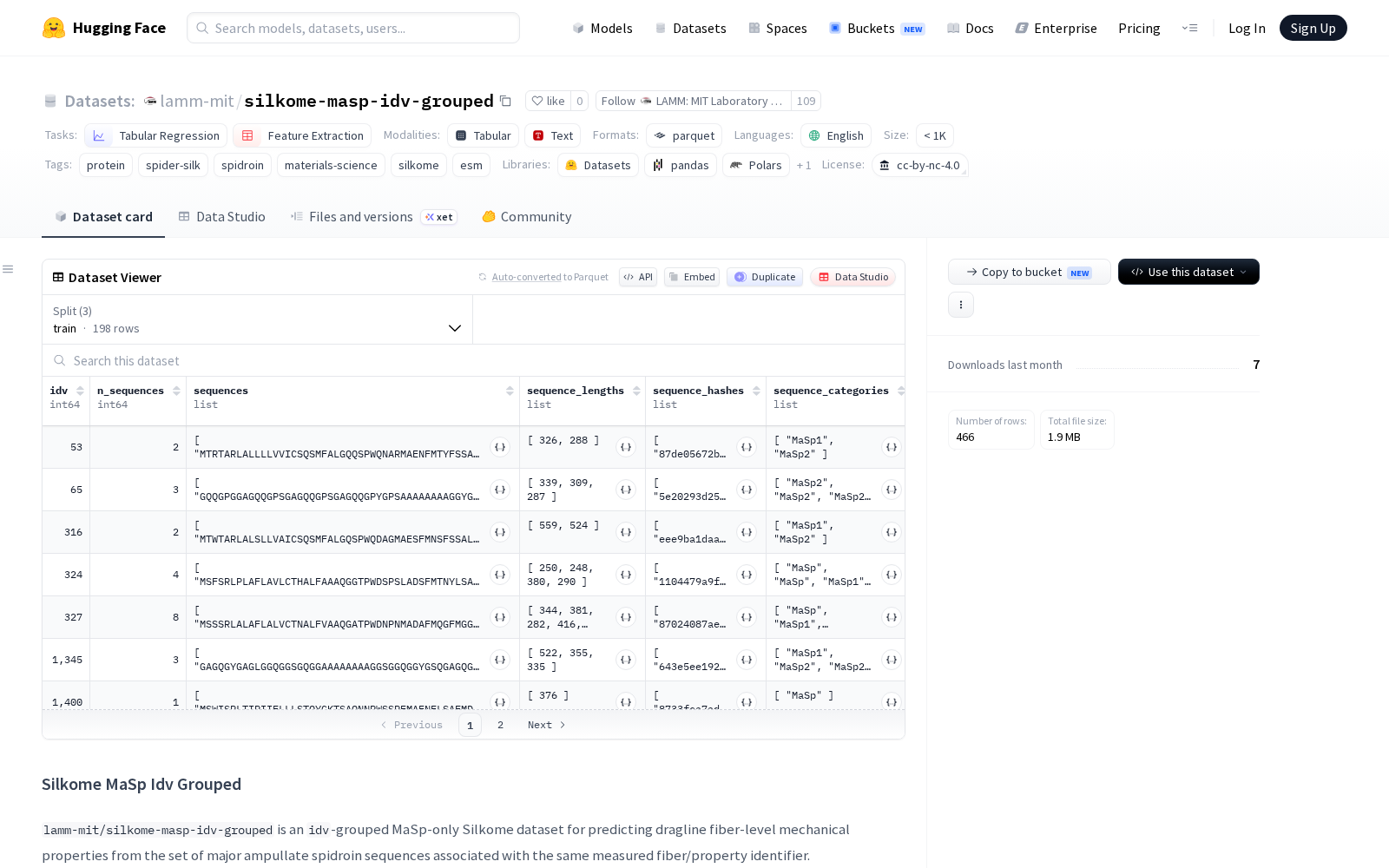
从数据规模与划分逻辑来看,该数据集共包含233个唯一的idv分组样本,按照源数据集的benchmark_split规则划分为训练集(198个样本)和测试集(35个样本),划分过程严格保证训练集与测试集在idv和四元组属性上零重叠,从数据集底层设计上避免了模型训练过程中的数据泄露问题。分组前共有1033个源序列行,分组后每个idv包含的序列数量中位数为4,单条序列的最大长度为5896个残基,覆盖了MaSp、MaSp1、MaSp2、MaSp2B、MaSp3、MaSp3B等所有已知的主要壶腹丝蛋白类别,数据代表性覆盖绝大多数已知蜘蛛物种的丝蛋白序列特征。
为降低科研人员的使用门槛,每个样本都提供了多维度的完整信息:包含氨基酸序列列表、序列类别、长度、哈希值在内的详细序列信息,包含物种分类、性别、NCBI标识符、各类别丝蛋白计数统计在内的组成与元数据,以及韧性、杨氏模量、强度、应变四个关键的纤维力学性能目标值,同时附带有目标值的标准差和归一化版本,可直接适配不同模型的训练需求。此外数据集还额外提供了序列的FASTA格式文本、以25个‘X’残基连接的串联序列等多种表示形式,科研人员可根据研究需求直接调用,无需额外做数据预处理。
作为生命科学领域的核心数据要素资源,该数据集的应用场景覆盖多个前沿研发方向:首先可直接用于基于分组丝蛋白序列集的纤维级力学性能预测研究,特别是ESMC嵌入结合集合聚合(如平均池化、注意力池化、DeepSets、集合变换器)的模型基准测试,其按idv划分的设计相比随机序列级划分能提供更安全的防数据泄露评估,大幅提升模型性能验证的可信度;其次可用于蛋白质序列-性质关系挖掘,科研人员可基于该数据集分析不同MaSp亚型的组合模式与纤维宏观性能的关联,挖掘决定丝蛋白力学性能的关键序列特征;此外该数据集还可为合成生物学领域的人工蜘蛛丝研发提供设计参考,指导科研人员定向改造丝蛋白序列,研发适配不同场景的高性能仿生材料,比如超高强度的医用缝合线、轻量化的航空航天结构材料、可完全降解的环保纺织材料等,其构建逻辑也可为蚕丝、角蛋白等其他结构蛋白的数据集建设提供参考。
值得注意的是,该数据集的目标值为纤维级别的宏观测量结果,并非单个蛋白质的直接标签,真实场景下的纤维性能还受实验条件、环境参数、纺丝工艺、蛋白空间结构及翻译后修饰等多种因素影响,科研人员可基于该数据集的基础框架,结合其他维度的实验数据进一步拓展研究边界。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)