

随着AI for Science交叉领域的快速迭代,蛋白质大模型、计算驱动的生物材料设计已成为全球科研与产业界共同关注的重点方向,而覆盖序列、功能属性全链路的高质量标准化数据集,是支撑AI模型训练、降低研发试错成本的核心公共基础设施。作为具备高强度、高韧性、轻量化、生物可降解等多重优势的天然高性能纤维,蜘蛛丝的仿生设计与产业化应用长期受限于数据碎片化问题:公开领域一直缺乏统一的丝蛋白序列与对应纤维机械属性的配对基准数据集,不同研究团队的实验数据标准不一,难以支撑通用AI模型的训练与跨研究的结果对比。麻省理工学院(MIT)原子与分子力学实验室(LAMM)是全球原子级材料建模、生物材料力学机制研究领域的顶尖机构,长期聚焦多尺度材料模拟、分子级材料设计相关研究,其本次发布的silkome-masp数据集,正是针对上述行业痛点打造的专用科研数据集。
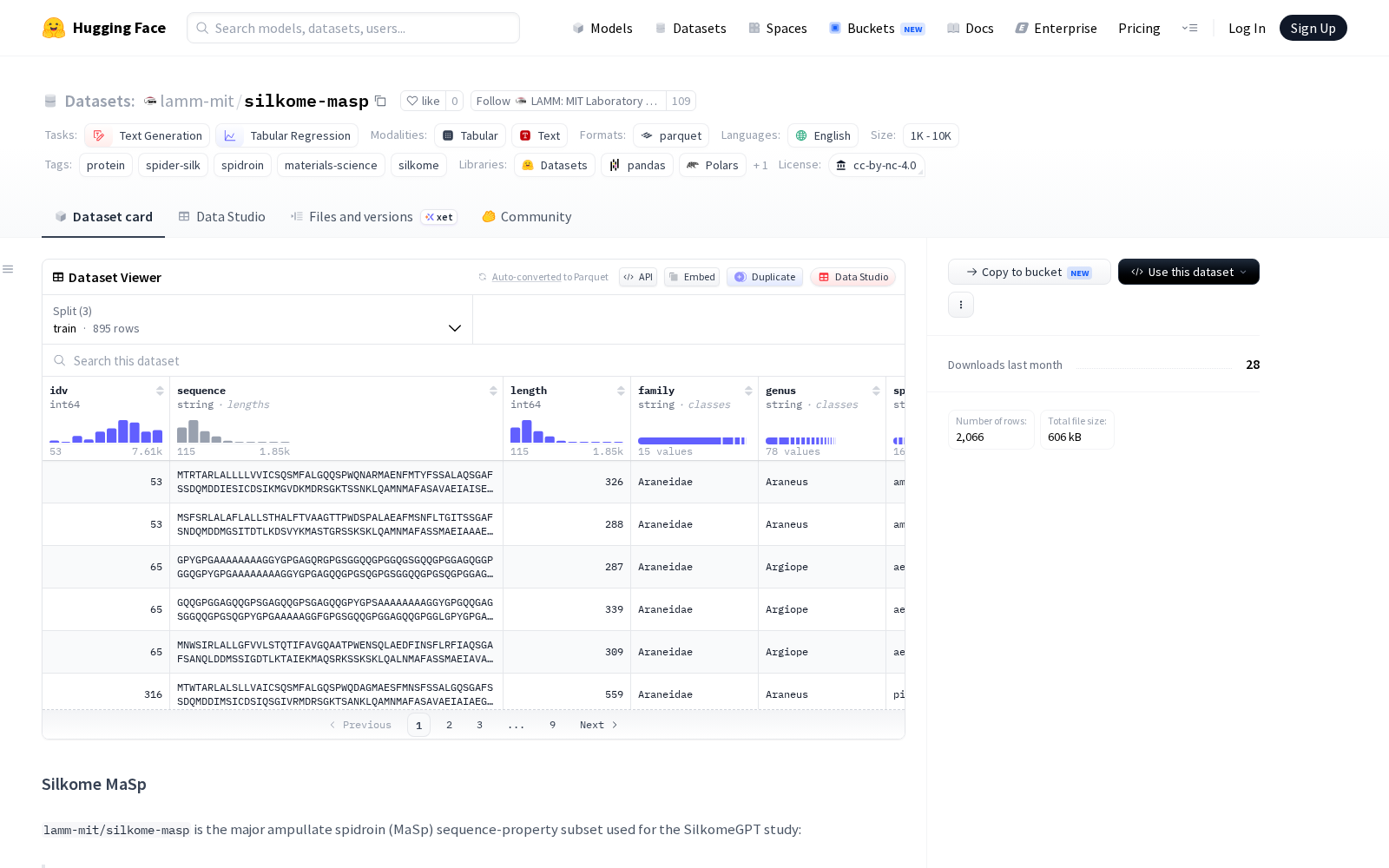
据介绍,silkome-masp是一款聚焦主壶腹丝蛋白(MaSp)的序列-属性配对数据集,核心服务于SilkomeGPT相关研究。该数据集从完整的silkome-full数据集中筛选出category1标注为MaSp、MaSp1、MaSp2、MaSp2B、MaSp3、MaSp3B的有效条目,核心目标是构建标准化的MaSp类蛋白序列到纤维属性的对应关系,实现蛋白质级的丝蛋白序列与纤维级的机械测量值的一一配对。目前该数据集共包含1033行有效数据,覆盖1028个独特的氨基酸序列、233个独特的纤维/属性标识符(idv),序列长度范围从115到1854个氨基酸,中位数为378,可覆盖绝大多数主壶腹丝蛋白的序列特征。为适配AI模型训练需求,数据集专门提供了完整集(full)、训练集(train)和测试集(test)三种分割方式,其中基准分割采用确定性随机分组方法,以idv为单位进行分组,确保训练集和测试集之间在idv和属性元组上均无重叠,从根源上避免数据泄漏问题,保证模型训练与评估结果的可靠性。
从字段构成来看,该数据集覆盖三类核心信息:第一类为序列与基础元数据,包括idv、氨基酸序列、序列长度、category1/category2分类学信息、物种信息、来源分割、基准分割等;第二类为8项核心无缺失的纤维级机械属性,具体包括韧性及其标准差、杨氏模量E及其标准差、强度及其标准差、应变及其标准差,覆盖了丝纤维材料性能评价的核心指标;第三类为上述核心属性的归一化版本,共同构成SilkomeGPT条件生成中使用的8维属性向量,此外数据集还保留了部分额外的材料属性列,可支撑更多维度的研究需求。
该数据集可广泛适用于蜘蛛丝蛋白语言建模、序列到属性预测、条件序列生成、蛋白质/材料设计工作流等多个研究方向。需要特别注意的是,数据集呈现的是一种弱监督关系:机械测量目标为纤维级结果,而每个序列对应蛋白质级丝蛋白序列,由于蜘蛛丝纤维本身是复杂的多组分材料,多个丝蛋白序列可能共享相同的测量纤维属性,研究人员可基于这一特性开展蛋白质领域的弱监督学习算法相关研究。从应用价值来看,基于该数据集,研究团队可定向训练蛋白生成模型,设计具备特定韧性、强度、应变属性的新型丝蛋白,潜在应用覆盖医用高强度可吸收缝合线、轻量化航空航天结构材料、高性能个体防护装备、可穿戴柔性电子基底等多个产业场景,对推动高性能仿生材料的研发落地具有重要支撑作用。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)