

当前大模型智能体正加速向各行业复杂业务场景渗透,其中面向长周期分析、多轮决策需求的分析类智能体,已成为企业数字化转型、科研效率提升的核心工具之一。但长期以来,行业针对智能体数据分析能力的评估多集中于单轮、独立问题的解答准确率,与真实场景中多轮交互、分析状态动态演化的需求存在明显 gap,始终缺乏适配真实工作流的标准化基准测试工具。作为国内NLP领域的顶尖研究团队,浙江大学自然语言处理实验室(ZJUNLP)长期深耕大模型推理、智能体交互等方向的技术研究,此次发布的LongDS数据集正是针对上述行业痛点打造的核心成果。
LongDS(LongDS-Bench)是国内首个专门用于评估长周期、多轮次智能体数据分析能力的基准测试数据集。在现实世界的数据分析中,分析过程很少是一系列独立的问题序列,而是涉及过滤器、指标定义、假设、中间表以及分支特定结果等分析状态在多次交互中不断演化的过程。LongDS 旨在测试智能体是否能够正确维护并应用这些不断演化的分析状态,还原真实业务中的数据分析全流程。
该数据集包含从真实世界的 Kaggle 笔记本和数据集中构建的 68 个任务,覆盖了商业、社区、教育、地球科学、社会公益和体育六个领域,总计包含 2,225 轮次交互。这些任务涵盖了具有代表性的6类真实分析状态演化模式,包括:初始分析状态构建(对应从零搭建分析框架、梳理口径逻辑)、状态继承(对应承接上一轮分析结论向下深挖问题)、状态更新(对应根据新增数据调整分析逻辑)、反事实扰动(对应模拟变量变化后的测算分析)、回滚至早期状态(对应推翻错误结论回到之前节点重算)以及多状态组合(对应跨分析分支的结论整合),完整覆盖了商业分析、科研数据处理等场景下的高频操作需求。
数据集的结构包括一个任务索引文件(task_list.json),其中列出了每个任务所属的领域、使用的数据集名称和任务ID。每个具体任务对应一个目录,其中包含任务定义文件(如 task.ipynb, task.py, task.json)和元数据文件(metadata.json)。相关的数据文件则存放在对应的数据目录中,方便开发者和研究人员快速调用测试。
从应用价值来看,产业侧布局分析类智能体的大模型厂商、企业数字化部门,可通过LongDS的标准化测试精准识别智能体在长周期分析中的上下文记忆偏差、逻辑断层等问题,优化产品能力,为金融经营分析、零售用户运营诊断、科研数据处理、公共政策评估等场景输出更可靠的智能工具;科研侧从事智能体推理、长上下文建模、多轮决策研究的学术团队,也可将LongDS作为通用测试基准,统一不同研究方向的能力评估标尺,推动相关技术的高效迭代。
Dataset card内容:
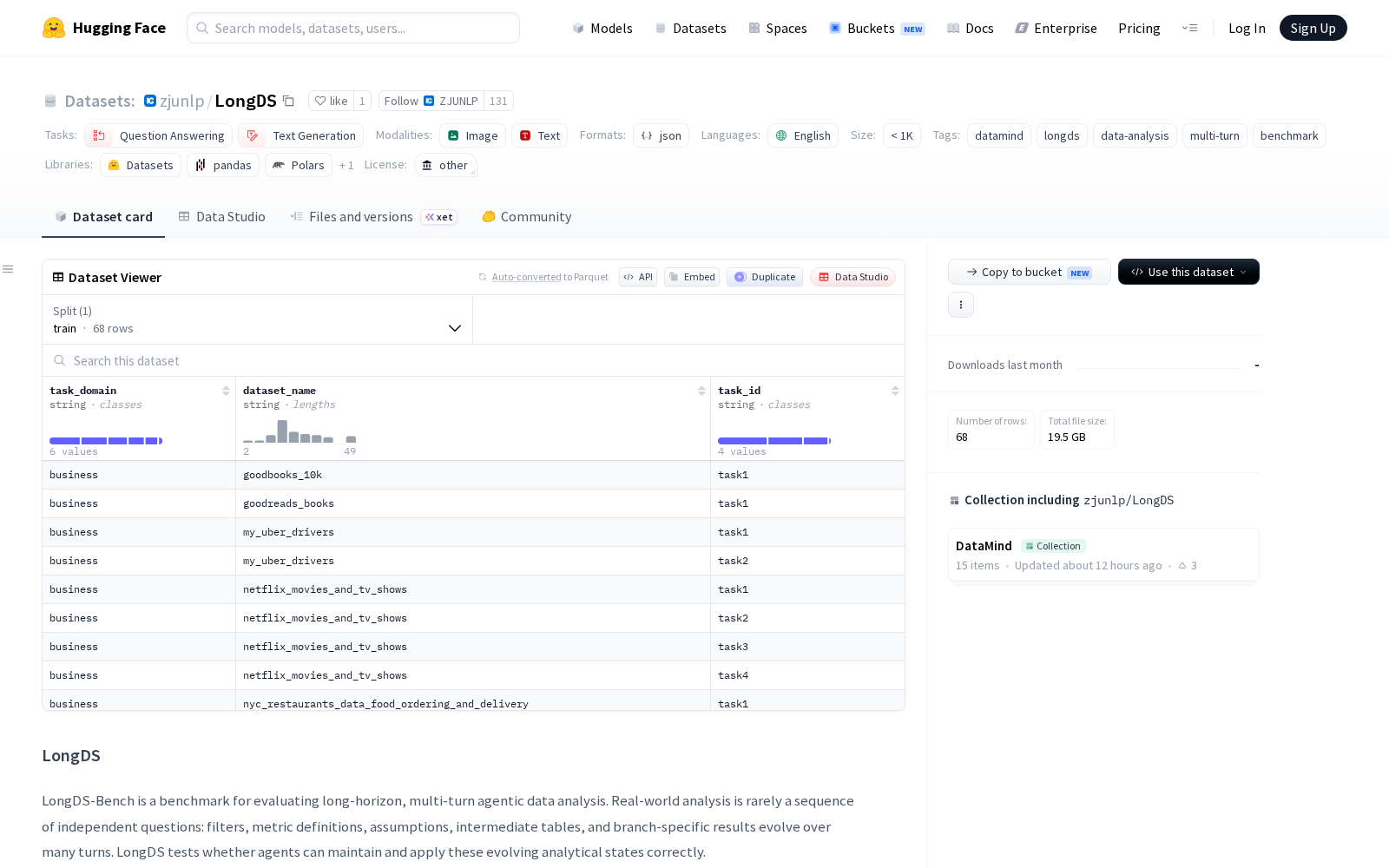
Files and versions内容:



_1769672084863.jpg)