

随着多模态大语言模型技术的快速迭代,其在复杂物理场景下的空间理解与推理能力,已成为决定自动驾驶、具身智能等领域商业化落地速度的核心指标。但长期以来,行业内缺乏针对360度全景图像场景的多步推理基准数据集,现有测试基准普遍存在问题设计难度偏低、未充分挖掘全景图像全局视野价值的缺陷,导致模型的空间推理能力评估缺乏统一、科学的衡量标准。近日,上海交通大学联合香港科技大学(广州)等机构共同构建的全球多步全景推理基准数据集OmniCoT正式发布,该数据集于2026年6月29日首发于学术平台arXiv,旨在推动多模态大语言模型在360度全景图像中的复杂空间推理能力升级。据介绍,OmniCoT数据集共包含21.6K条高质量问答对,覆盖4.2K张全景图像,通过自动化标注与人工校验相结合的混合流程生成,所有问答对均附有结构化的逐步思维链注释。其创建过程创新性采用三维场景几何到结构化语言表示的转换逻辑,遵循“观察-定位-移动”的渐进式问题分类法,确保所有问题的解答均需要模型完成多跳推理与全局信息整合,从根源上规避了现有基准的设计缺陷。该数据集主要应用于全景空间推理、多跳视觉问答两大领域的模型训练与效果评估,下游可覆盖多个高潜力场景:在具身智能领域,可用于训练服务机器人、工业巡检机器人的陌生环境空间感知能力,支撑机器人完成路径规划、动态避障、目标定位等复杂任务;在自动驾驶领域,可用于优化车载环视感知模型的全局信息整合能力,提升多目标同时追踪、复杂路况预判的准确率;在数字孪生与智慧城市领域,可支撑全景监控系统的异常事件定位、运维路线自动生成等功能的研发。作为AI训练数据要素领域的垂直类基准数据集,OmniCoT的发布也将进一步完善我国多模态大模型研发的供给体系,为相关技术的标准化、产业化落地提供核心支撑。
Dataset card内容:
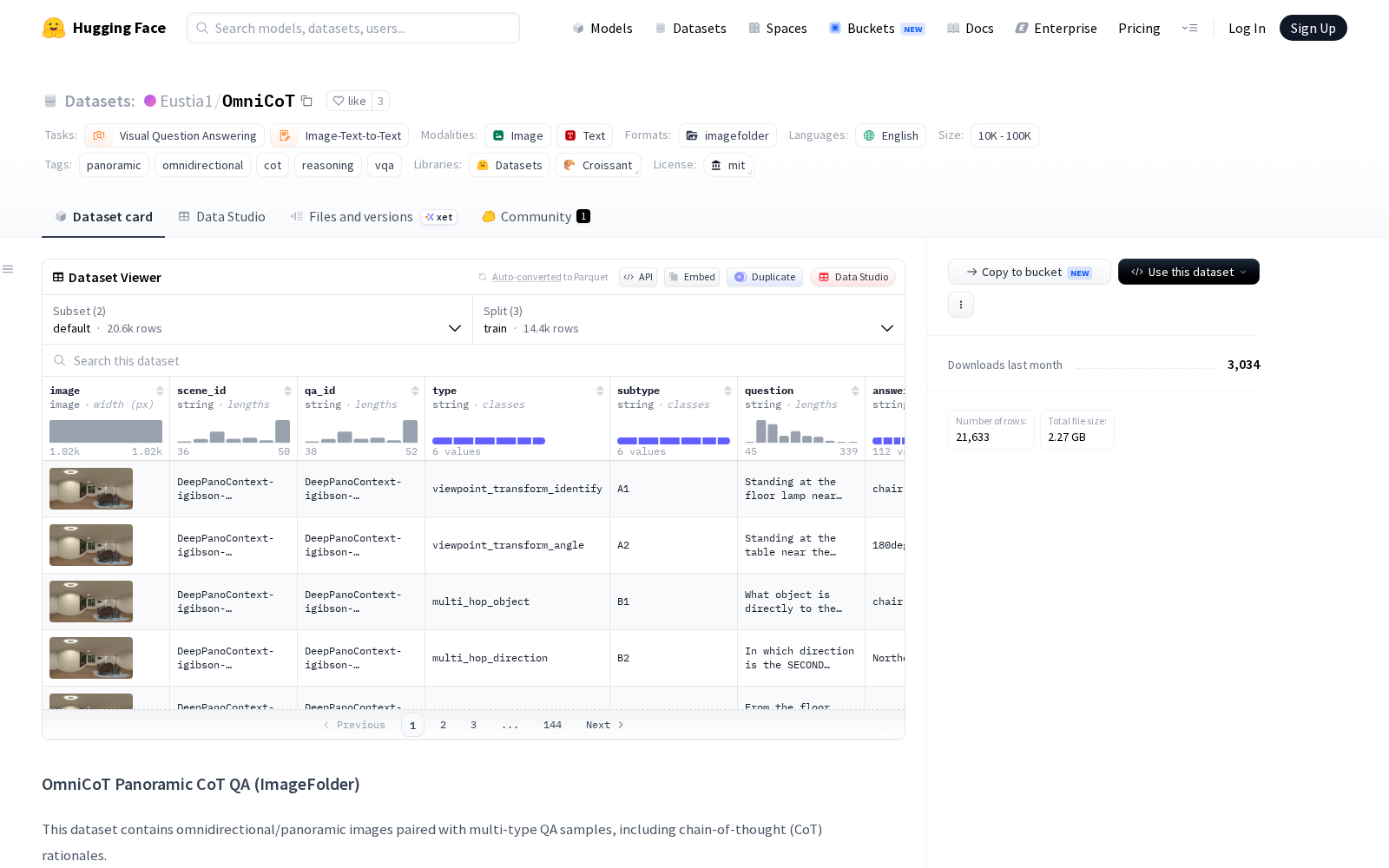
Files and versions内容:



_1769672084863.jpg)