

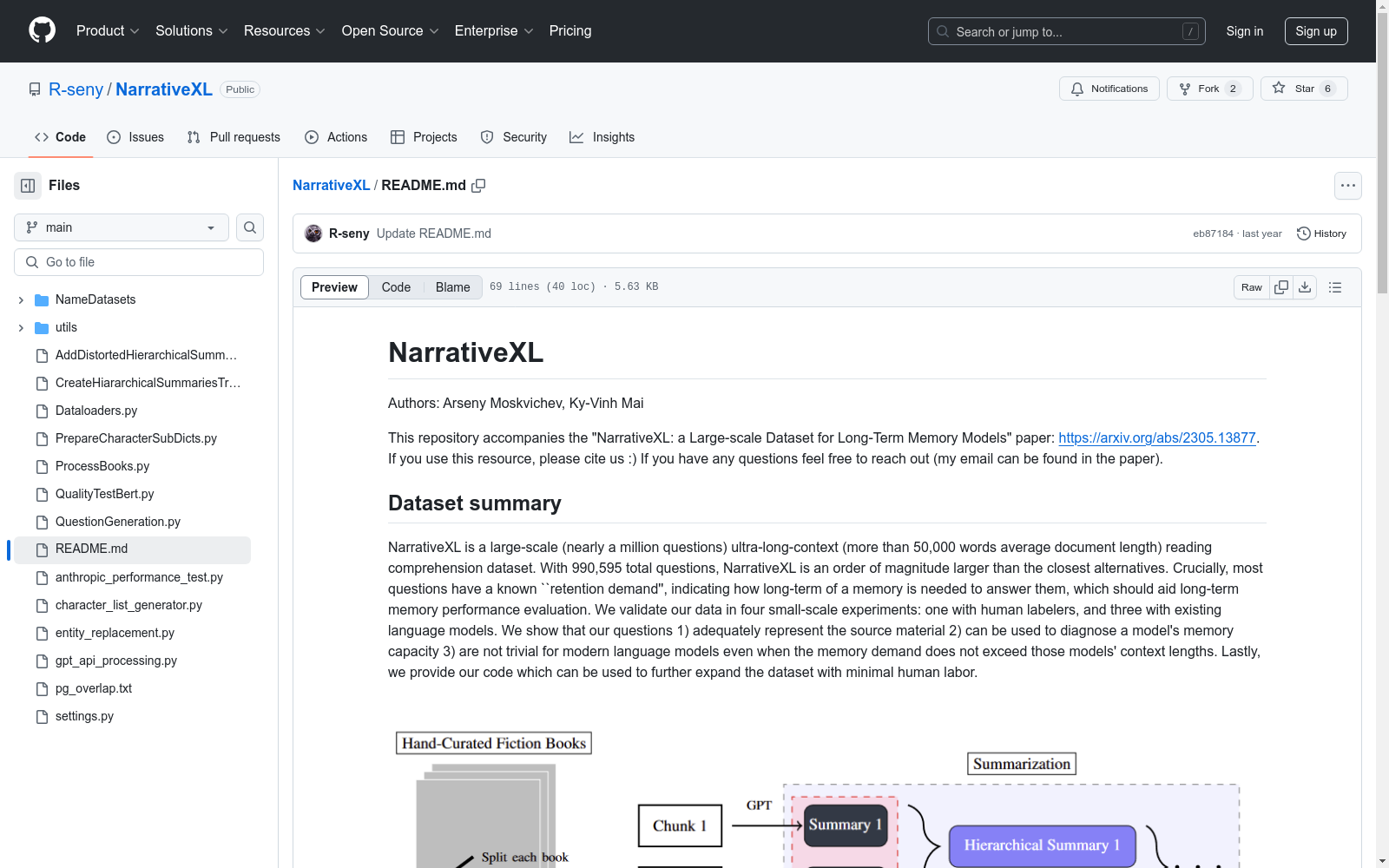
圣菲研究所 本次发布的数据集 NarrativeXL, NarrativeXL是一个大规模的阅读理解数据集,包含近百万个问题,平均文档长度超过50,000字,适用于长期记忆模型的训练和评估。该数据集利用GPT-3.5从Project Gutenberg的1500本手工精选小说中总结每个场景,每本书约产生150个场景级总结。随后,基于这些总结创建了多种阅读理解问题,包括三种类型的多选场景识别问题以及自由形式的叙事重建问题。数据集的关键特点是大多数问题具有已知的“保留需求”,指示回答这些问题所需的长期记忆程度,有助于评估长期记忆性能。此外,数据集还提供了代码,以便以最小的劳动力成本进一步扩展数据集。该数据集适用于开发和评估需要处理极长上下文的语言模型,旨在解决现有模型在处理长文本时性能下降的问题。
README 内容:
关于 圣菲研究所 , 圣菲研究所(Santa Fe Institute,简称SFI)是一个位于美国新墨西哥州圣菲的研究机构,专注于复杂系统科学的研究。该研究所成立于1984年,致力于跨学科研究,涉及物理学、生物学、社会科学等多个领域,旨在理解和解释复杂系统的行为和结构。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)