

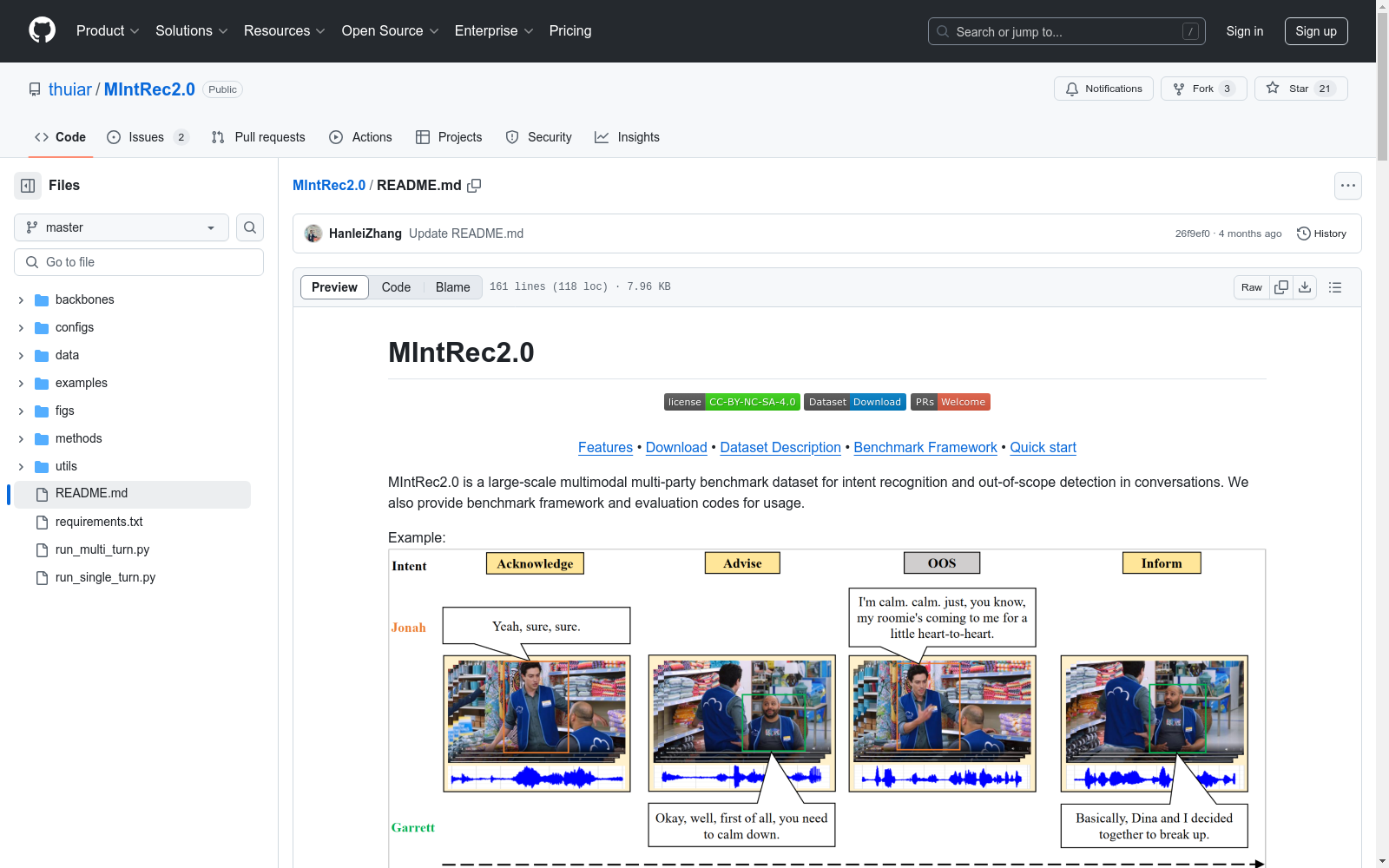
清华大学 本次发布的数据集 MIntRec2.0, MIntRec2.0是由清华大学创建的大规模多模态意图识别基准数据集,包含1,245个高质量对话,总计15,040个样本,涵盖文本、视频和音频模态。数据集不仅包含超过9,300个范围内样本,还包括超过5,700个多轮对话中自然出现的范围外样本,增强了其实际应用性。数据集创建过程中,首先收集了三个电视剧的原始视频,并根据时间戳分割成话语级别的片段,然后手动将这些片段分组成对话,以匹配对话场景和事件。随后,为每个话语标注了说话者身份信息,以便利用特定的上下文信息。数据集的应用领域包括人机对话交互,旨在解决高级认知意图理解任务,显著促进了相关研究。
README 内容:
关于 清华大学 , 清华大学,位于中国北京,是一所享誉全球的顶尖研究型大学,以其深厚的学术底蕴和杰出的科研能力而著称。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。


_1769672084863.jpg)