

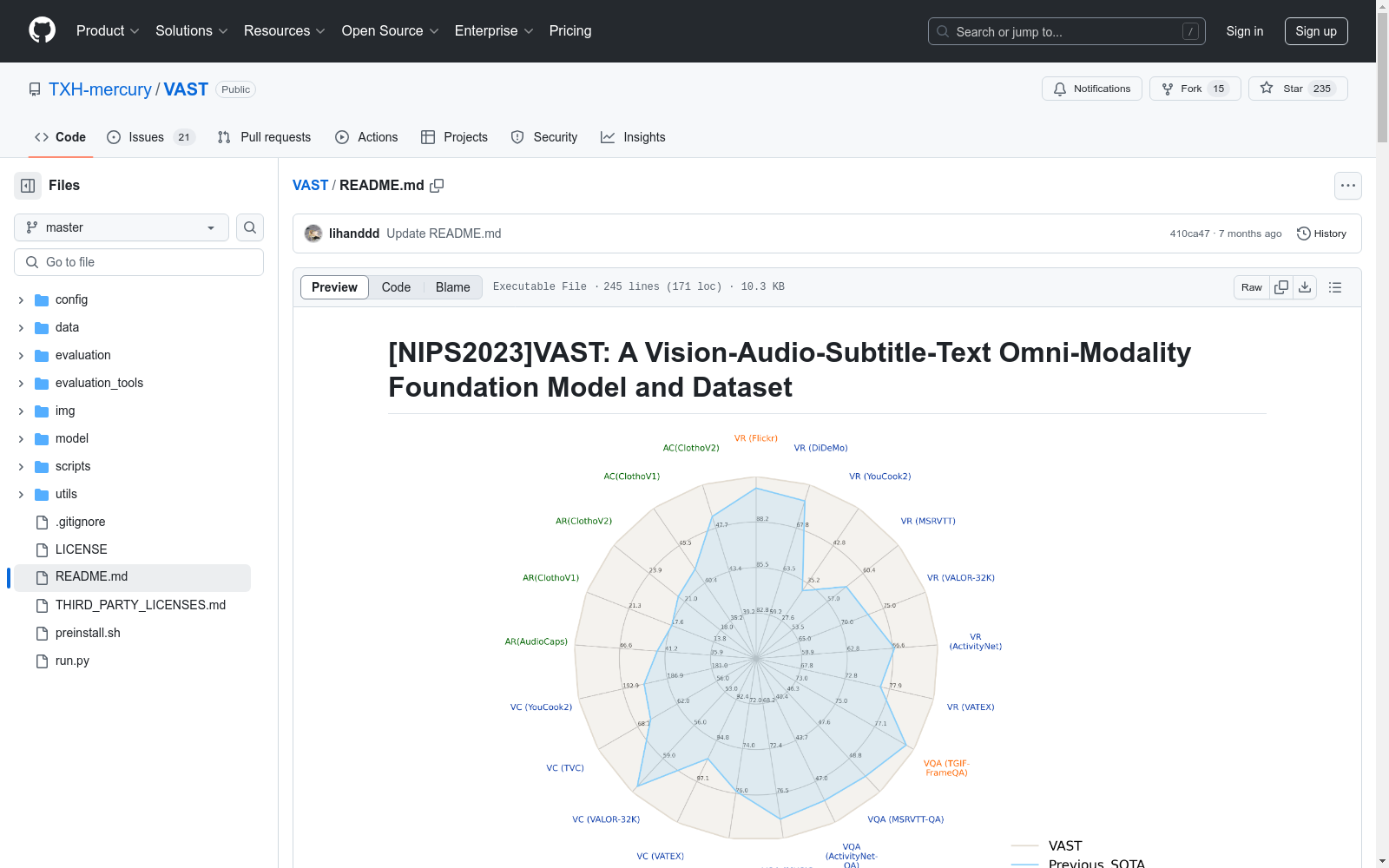
中国科学院自动化研究所 本次发布的数据集 VAST-27M, VAST-27M是由中国科学院自动化研究所创建的大规模全模态视频字幕数据集,包含2700万个视频片段。每个视频片段都配有视觉、音频和字幕模态的字幕,这些字幕是通过训练单独的视觉和音频字幕生成器以及使用大型语言模型Vicuna-13b整合生成的。数据集的创建旨在推动多模态视频-文本预训练模型的研究,特别是在视觉-文本、音频-文本和全模态视频-文本任务中。VAST-27M数据集的应用领域广泛,包括视频内容理解、视频检索、视频字幕生成和视频问答等。
README 内容:
关于 中国科学院自动化研究所 , 中国科学院自动化研究所是中国科学院下属的研究机构,主要从事自动化科学与技术的研究,涵盖人工智能、机器人技术、模式识别等多个领域。
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。



_1769672084863.jpg)