

4月29日刚刚突破2000万大关,仅隔27天——5月26日,全球数据集搜索引擎“遇见数据集”再度刷新里程碑,平台已收录的全球数据资源总量正式突破 3000万!不到一个月的时间,千万级新增的背后,是“遇见数据集”持续加速的全球数据发现能力与不断进化的索引平台实力。
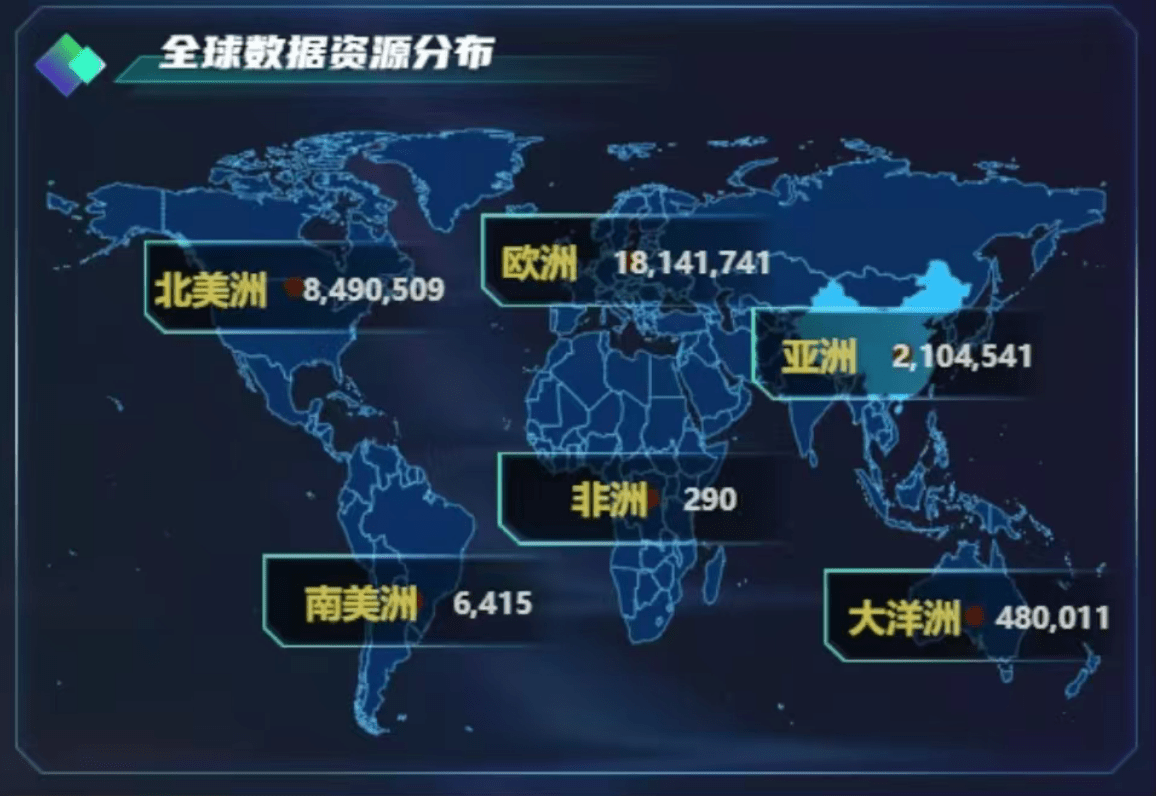
全球数据版图极速扩张,27天绘就更密集的“数据地图”
从4月29日到5月26日,“遇见数据集”的智能数据发现引擎昼夜不停地穿梭于全球数万个数据源,将政府开放平台、科研机构数据库、商业数据市场等散落各处的数据集一一发现、清洗、标引入库。3000万的收录总量,不仅意味着全球数据版图上更多节点被点亮,更意味着每一位开发者、研究者搜索所需数据时,“遇见”好数据的概率正在以肉眼可见的速度攀升。
中国数据同步跃升,深度覆盖关键行业
在全球数据猛增的同时,平台聚焦中国本土的数据收录也跑出了同样的加速度。截至目前,“遇见数据集”收录的中国数据集已突破 144万,广泛分布在金融、医疗、交通、气象、农业、工业互联网、地理空间等多个行业。无论是政务数据的精准开放,还是产业数据的高效对接,这张越来越密的中国数据网络,正帮助本土创新者更快找到身边的“数据宝藏”。
不止于“快”:让数据可发现、可理解、可应用
收录速度的背后,是“遇见数据集”独有的技术底色。平台不仅通过高频发现保证数据“鲜度”,更依赖自动标注、格式识别、智能分类与质量筛选等能力,让海量数据不止于“被收录”,更能被精准检索、快速理解、直接应用。正是这种“发现即可用”的体验,支撑起了千万级增长的跳跃。
展望:从3000万到星辰大海
遇见数据集团队表示,将继续加大在数据发现广度、更新频率和智能理解上的投入,在数据源头与数据应用之间架设更高效的桥梁,助力AI时代每一次创新,都能从“遇见”好数据开始。
从4月29日的2000万,到5月26日的3000万,27天,是速度,更是起点。下一次突破,已在路上!



_1769672084863.jpg)